前端性能优化方案
关于 Web 应用性能优化,有一点是毫无疑问的:「页面加载越久,用户体验就越差」。Web 应用性能优化的关键之处就在于:减少页面初载时所需加载资源的「数量」和「体积」。
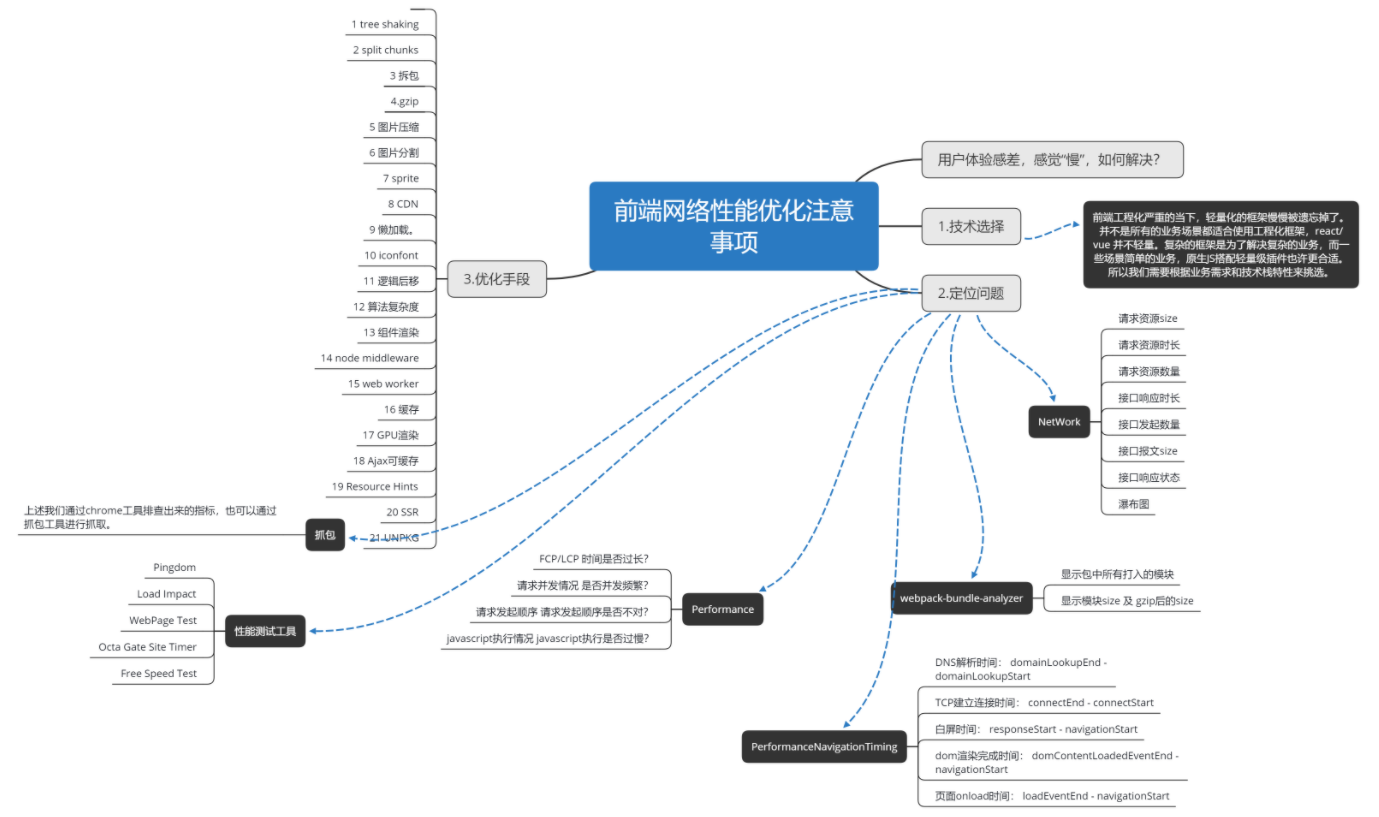
下面是说明性能良好的一个参考值,该参考值考虑到了移动端等多种访问环境:
- 页面初载时,所有未压缩的 JavaScript 脚本大小**<=200KB**;
- 页面初载时,所有未压缩的 CSS 资源大小**<=100KB**;
- HTTP 协议下,请求资源数**<=6 个**;
- HTTP/2 协议下,请求资源数**<=20 个** ;
- **90%**的代码利用率(仅允许 10% 的未使用代码);
(一)分析性能工具
1. Chrome 开发者工具
NetWork 面板
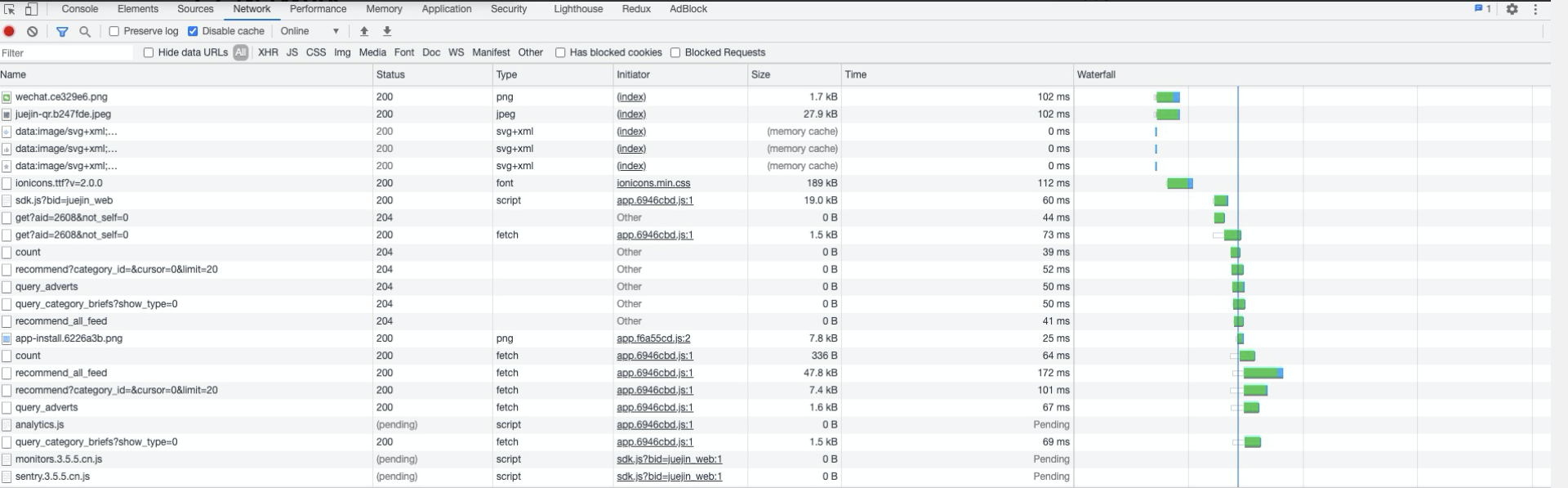
从 NetWork 面板上可以看到如下信息:
- 请求资源 size
- 请求资源时长
- 请求资源数量
- 接口响应时长
- 接口发起数量
- 接口报文 size
- 接口响应状态
- 瀑布图
1. 瀑布图
瀑布图是上方图片后面的waterfall纵列,它是一个级联图,展示了浏览器如何加载资源并渲染成网页。图中的每一行都是一次单独的浏览器请求。这个图越长,说明加载网页过程中所发的请求越多。每一行的宽度,代表浏览器发出请求并下载该资源的过程中所耗费的时间。它的侧重点在于分析网路链路
瀑布图颜色说明:
- DNS Lookup [深绿色]:在浏览器和服务器进行通信之前,必须经过 DNS 查询,将域名转换成 IP 地址。在这个阶段,你可以处理的东西很少。但幸运的是,并非所有的请求都需要经过这一阶段。
- Initial Connection [橙色]:在浏览器发送请求之前,必须建立 TCP 连接。这个过程仅仅发生在瀑布图中的开头几行,否则这就是个性能问题 (后边细说).
- SSL/TLS Negotiation [紫色]:如果你的页面是通过 SSL/TLS 这类安全协议加载资源,这段时间就是浏览器建立安全连接的过程。目前 Google 将 HTTPS 作为其 搜索排名因素 之一,SSL/TLS 协商的使用变得越来越普遍了。
- Time To First Byte (TTFB) [绿色]:TTFB 是浏览器请求发送到服务器的时间 + 服务器处理请求时间 + 响应报文的第一字节到达浏览器的时间。我们用这个指标来判断你的 web 服务器是否性能不够,或者说你是否需要使用 CDN.
- Downloading [蓝色]:这是浏览器用来下载资源所用的时间。这段时间越长,说明资源越大。理想情况下,你可以通过控制资源的大小来控制这段时间的长度。
那么除了瀑布图的长度外,我们如何才能判断一个瀑布图的状态是健康的呢?
- 首先,减少所有资源的加载时间。亦即减小瀑布图的宽度。瀑布图越窄,网站的访问速度越快;
- 其次,减少请求数量 也就是降低瀑布图的高度。瀑布图越矮越好;
- 最后,通过优化资源请求顺序来加快渲染时间。从图上看就是将绿色的”开始渲染”线向左移。这条线向左移动的越远越好。
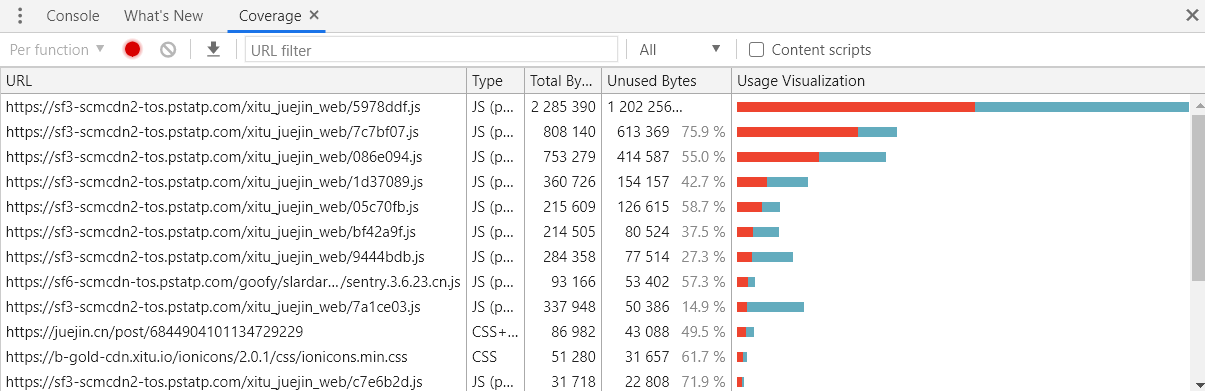
2. 代码利用率
你可能会困惑在实际开发中如何得到这个值,别担心,通过使用 Chrome 开发者工具(很遗憾,目前只有 Chrome 支持这一功能),你就可以迅速对你的 Web 应用进行分析,得到当前页面下的代码利用率状态,步骤如下:
① 打开 Chrome 开发者工具后,按下 Ctrl + Shift + P ;
② 输入 Coverage,并选择第一个出现的选项;

③ 点击面板上的 reload 按钮,查看整个应用 JavaScript 的代码利用率;

Performance 面板
chrome 自带的 performance 模块。先附上一个官网文档传送门:Performance
从上图中可以分析出一些指标
- FCP/LCP 时间是否过长?
- 请求并发情况 是否并发频繁?
- 请求发起顺序 请求发起顺序是否不对?
- javascript 执行情况 javascript 执行是否过慢?
webpack-bundle-analyzer
项目构建后生成的 bundle 包是压缩后的。webpack-bundle-analyzer 是一款包分析工具。效果如下图:
其中模块面积占的越大说明在 bundle 包中 size 越大,重点优化一下。它能够排查出来的信息有
- 显示包中所有打入的模块
- 显示模块 size 及 gzip 后的 size
排查包中的模块情形是非常有必要的,通过 webpack-bundle-analyzer 来排查出一些无用或过大的模块。然后进行优化,以减少 bundle 包 size,减少加载时长。
安装
1 | # NPM |
使用 (as a Webpack-Plugin)
1 | const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin; |
然后构建包完毕后会自动弹出一个窗口展示上图信息。
Performance Navigation Timing
获取各个阶段的响应时间,我们所要用到的接口是Performance Navigation Timing接口。
Performance Navigation Timing 提供了用于存储和检索有关浏览器文档事件的指标的方法和属性。例如,此接口可用于确定加载或卸载文档需要多少时间。
1 | function showNavigationDetails() { |
使用这个函数,我们就可以获取各个阶段的响应时间,如图:

参数说明
- navigation Start:加载起始时间
- redirect Start:重定向开始时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回开始重定向的 fetch Start 的值。其他情况,则返回 0)
- redirect End:重定向结束时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回最后一次重定向接受完数据的时间。其他情况则返回 0)
- fetch Start:浏览器发起资源请求时,如果有缓存,则返回读取缓存的开始时间
- domain Lookup Start:查询 DNS 的开始时间。如果请求没有发起 DNS 请求,如 keep-alive,缓存等,则返回 fetch Start
- domain Lookup End:查询 DNS 的结束时间。如果没有发起 DNS 请求,同上
- connect Start:开始建立 TCP 请求的时间。如果请求是 keep-alive,缓存等,则返回 domain Lookup End
- secure Connection Start:如果在进行 TLS 或 SSL,则返回握手时间
- connect End:完成 TCP 链接的时间。如果是 keep-alive,缓存等,同 connect Start
- request Start:发起请求的时间
- response Start:服务器开始响应的时间
- dom Loading:从图中看是开始渲染 dom 的时间,具体未知
- dom Interactive:未知
- dom Content Loaded Event Start:开始触发 Dom Content Loaded Event 事件的时间
- dom Content Loaded Event End:返回 Dom Content Loaded Event 事件结束的时间
- dom Complete:从图中看是 dom 渲染完成时间,具体未知
- load Event Start:触发 load 的时间,如没有则返回 0
- load Event End load:事件执行完的时间,如没有则返回 0
- unload Event Start unload:事件触发的时间
- unload Event End unload:事件执行完的时间
关于 Web 性能,我们会用到的时间参数:
DNS 解析时间:domain Lookup End - domain Lookup Start
TCP 建立连接时间:connect End - connect Start
白屏时间:response Start - navigation Start
dom 渲染完成时间:dom Content Loaded Event End - navigation Start
页面 onload 时间:load Event End - navigation Start
根据这些时间参数,我们就可以判断哪一阶段对性能有影响。
性能测试工具
2.7.1 Pingdom
2.7.2 Load Impact
2.7.3 WebPage Test
2.7.4 Octa Gate Site Timer
2.7.5 Free Speed Test
(二)定义环境
1. CDN
① CDN 概述
CDN 的全称是 Content Delivery Network,即内容分发网络。我们访问一个网站页面时,会向服务器请求很多网络资源,包括各种图片、声音、影片、文字等信息。网站可以预先把内容分发至全国各地的加速节点,这样用户就可以就近获取所需内容,避免网络拥堵、地域、运营商等因素带来的访问延迟问题,有效提升下载速度、降低响应时间,提供流畅的用户体验。
CDN 技术消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量。广泛分布的 CDN 节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种 DDoS 攻击对网站的影响,同时保证较好的服务质量。在项目中有很多东西都是放在 CDN 上的,比如:静态文件,音频,视频,js 资源,图片。把静态资源度放在 CDN 上,可以加快资源加载的速度。
传统网站的请求响应过程一般经历以下步骤:
- 用户在自己的浏览器中输入要访问的网站域名。
- 浏览器向本地 DNS 服务器请求对该域名的解析,即该域名相应的服务设备的 IP 地址。
- 本地 DNS 服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求。如果没有关于这个域名的解析结果的缓存,则以迭代方式向整个 DNS 系统请求解析,获得应答后将结果反馈给浏览器。
- 浏览器获取 IP 地址之后,经过标准的 TCP 握手流程,建立 TCP 连接。
- 浏览器向服务器发起 HTTP 请求。
- 服务器将用户请求内容传送给浏览器。
- 经过标准的 TCP 挥手流程,断开 TCP 连接。
引入 CDN 之后,用户访问网站一般经历以下步骤:
当用户点击网站页面上的内容 URL,先经过本地 DNS 系统解析,如果本地 DNS 服务器没有相应域名的缓存,则本地 DNS 系统会将域名的解析权交给 CNAME 指向的CDN 专用 DNS 服务器。
CDN 的 DNS 服务器将 CDN 的全局负载均衡设备IP 地址返回给用户。
用户向 CDN 的全局负载均衡设备发起 URL 访问请求。
CDN 全局负载均衡设备根据用户 IP 地址和用户请求的 URL,选择一台用户所属区域的区域负载均衡设备,并将请求转发到此设备上。
基于以下这些条件的综合分析之后,区域负载均衡设备会选择一个最优的缓存服务器节点,并从缓存服务器节点处得到缓存服务器的 IP 地址,最终将得到的 IP 地址返回给全局负载均衡设备:
① 根据用户 IP 地址,判断哪一个边缘节点距用户最近;
② 根据用户所请求的 URL 中携带的内容名称,判断哪一个边缘节点上有用户所需内容;
③ 查询各个边缘节点当前的负载情况,判断哪一个边缘节点尚有服务能力;
④ 全局负载均衡设备把服务器的 IP 地址返回给用户;
⑤ 用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
② CDN 组成
内容分发网络(CDN)是由多个节点组成的。一般来讲,CDN 网络主要由中心节点、边缘节点两部分构成。
中心节点:包括 CDN 网管中心和全局负载均衡 DNS 重定向解析系统,负责整个 CDN 网络的分发及管理。
边缘节点:主要指异地分发节点,由负载均衡设备、高速缓存服务器两部分组成。
负载均衡设备负责每个节点中各个 Cache 的负载均衡,保证节点的工作效率;同时还负责收集节点与周围环境的信息,保持与全局负载均衡 DNS 的通信,实现整个系统的负载均衡。
高速缓存服务器(Cache)负责存储客户网站的大量信息,就像一个靠近用户的网站服务器一样响应本地用户的访问请求。通过全局负载均衡 DNS 的控制,用户的请求被透明地指向离它最近的节点,节点中 Cache 服务器就像网站的原始服务器一样,响应终端用户的请求。因其距离用户更近,故其响应时间才更快。
中心节点就像仓配网络中负责货物调配的总仓,而边缘节点就是负责存储货物的各个城市的本地仓库。
目前,很多提供 CDN 服务的云厂商在各地部署了多个 CDN 节点,拿阿里云举例,阿里云在全球拥有 2500+节点。中国大陆拥有 2000+节点,覆盖 34 个省级区域,大量节点位于省会等一线城市。海外和港澳台拥有 500+节点,覆盖 70 多个国家和地区。
③ CDN 相关技术
要想建设一个庞大的仓配网络,需要考虑四个方面:
- 如何妥善地将货物分发到各个城市的本地仓。
- 如何妥善地在各个本地仓存储货物。
- 如何根据用户的收货地址,智能匹配出应该优先从哪个仓库发货,选用哪种物流方式等。
- 对于整个仓配系统如何进行管理,如整体货物分发的精确度、仓配的时效性、发货地的匹配度等。
这些其实和 CDN 中最重要的四大技术不谋而合:
内容发布
它借助于建立索引、缓存、流分裂、组播(Multicast)等技术,将内容发布或投递到距离用户最近的远程服务点(POP)处。
内容存储
对于 CDN 系统而言,需要考虑两个方面的内容存储问题。一个是内容源的存储,一个是内容在 Cache 节点中的存储。
内容路由
它是整体性的网络负载均衡技术,通过内容路由器中的重定向(DNS)机制,在多个远程 POP 上均衡用户的请求,以使用户请求得到最近内容源的响应。
内容管理
它通过内部和外部监控系统,获取网络部件的状况信息,测量内容发布的端到端性能(如包丢失、延时、平均带宽、启动时间、帧速率等),保证网络处于最佳的运行状态。
(三)构建优化
1. tree shaking
App 往往有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树枝。实际情况中,虽然依赖了某个模块,但其实只使用其中的某些功能。通过 Tree shaking,将没有使用的模块摇掉,这样来达到删除无用代码的目的。
摇树是 webpack 构建优化中重要一环,用于清除项目中的一些无用代码,它依赖于 ES 中的模块语法。
1 | import _ from 'lodash' |
如上引用 lodash 库,在构建包的时候会把整个 lodash 包打入到 bundle 包。
1 | import _isEmpty from 'lodash/isEmpty'; |
而如上引用 lodash 库,在构建包的时候只会把 is Empty 这个方法抽离出来再打入到 bundle 包中。这样就会大大减少包的 size。在日常引用第三方库的时候,需要注意导入的方式。
如何开启摇树
在 webpack4.x 中默认对 tree-shaking 进行了支持。在 webpack2.x 中使用 tree-shaking:传送门
2. split chunks
在没配置任何东西的情况下,webpack 4 能够智能地实现代码分包:入口文件依赖的文件都被打包进了 main.js,而那些大于 30kb 的第三方包,如:echarts、xlsx、dropzone 等都被单独打包成了一个个独立 bundle。其它被我们设置了异步加载的页面或者组件变成了一个个 chunk,也就是被打包成独立的 bundle。
它内置的代码分割策略是这样的:
- 新的 chunk 是否被共享或者是来自 node_modules 的模块
- 新的 chunk 体积在压缩之前是否大于 30kb
- 按需加载 chunk 的并发请求数量小于等于 5 个
- 页面初始加载时的并发请求数量小于等于 3 个
大家可以根据自己的项目环境来更改配置。配置代码如下:
1 | splitChunks({ |
没有使用 webpack4.x 版本的项目,依然可以通过按需加载的形式进行分包,使得我们的包分散开,提升加载性能。
按需加载也是以前分包的重要手段之一,这里推荐一篇非常好的文章:webpack 如何使用按需加载
3. 拆包
上面 bundle 解析项目的技术栈是 react,但是 bundle 包中并没有 react、react-dom、react-router 等。因为这些插件被拆开了,并没有一起打包在 bundle 中,而是放在了 CDN 上。
假设原本 bundle 包为 2M,一次请求拉取。拆分为 bundle(1M) + react 桶(CDN)(1M)两次请求并发拉取。从这个角度来看,1+1 的模式拉取资源更快。
如果全量部署项目,每次部署 bundle 包都将重新拉取,这样比较浪费资源。可以对 react 桶命中强缓存,这样就算全量部署也只需要重新拉取左侧 1M 的 bundle 包即可,节省了服务器资源,优化了加载速度。
注意:在本地开发过程中,react 等资源建议不要引入 CDN,开发过程中刷新频繁,会增加 CDN 服务器压力,走本地就好。
Webpack Modes
除了 Webpack Chunk Name 注释外,Webpack 还提供了一些其他注释来对异步加载模块拥有更多控制权,示例如下:
1 | import ( |
webpack Mode 的默认值为 lazy,它会使所有异步模块都会被单独抽离成单一的 chunk,若设置该值为 lazy-once,Webpack 就会将所有带有标记的异步加载模块放在同一个 chunk 中。
Prefetch or Preload
通过添加 webpack Prefetch 魔术注释,Webpack 可以使用与 <link rel=“prefetch”> 相同的特性。让浏览器会在 Idle 状态时预先帮我们加载所需的资源,善用这个技术可以使我们的应用交互变得更加流畅。
1 | import( |
4. 缓存
缓存的原理就是更快读写的存储介质 + 减少 IO+减少 CPU 计算=性能优化。而性能优化的第一定律就是:优先考虑使用缓存。缓存的主要手段有:浏览器缓存、CDN、反向代理、本地缓存、分布式缓存、数据库缓存。
① Ajax 可缓存
Ajax 在发送的数据成功后,为了提高页面的响应速度和用户体验,会把请求的 URL 和返回的响应结果保存在缓存内,当下一次调用 Ajax 发送相同的请求(URL 和参数完全相同)时,它就会直接从缓存中拿数据。
在进行 Ajax 请求的时候,可以选择尽量使用 get 方法,这样可以使用客户端的缓存,提高请求速度。
(四)静态资源优化
1. 文件通用压缩
① Gzip 压缩
Ⅰ. gzip 概述
gzip 即GNUzip,是一个文件压缩程序,可以将文件压缩进后缀为.gz 的压缩包。而前端所讲的 gzip 压缩优化,就是通过 gzip 对资源进行压缩,从而降低请求资源的文件大小。
运用 gzip 压缩优化在业界十分普遍,基本上打开任何一个网站,它们的 html,js,css 文件都是经过 gzip 压缩的(即使 js,css 这类文件经过了混淆压缩之后,gzip 仍可以大幅优化文件体积)。通常 gzip 对纯文本内容可压缩到原大小的 40%,但 png、gif、jpg、jpeg 这类图片文件并不推荐使用 gzip 压缩(svg 例外),首先经过压缩后的图片文件 gzip 能压缩的空间很小。事实上,添加标头,压缩字典,并校验响应体可能会让它更大。
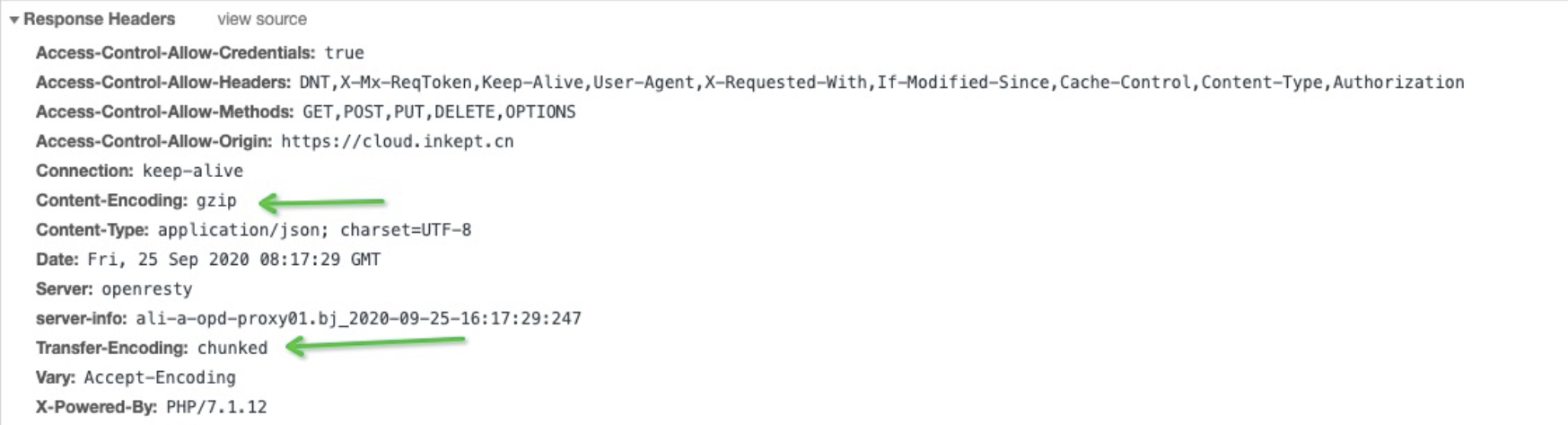
在访问网站时,打开调试工具,在网络请求 Network 中,任选一个 js 或 css,都能在 Response Headers 中找到 content-encoding: gzip 键值对,这就表示了该文件是启用了 gzip 压缩的。

在接到压缩请求时,压缩处理过程由服务器来实现:它会启动自己的 CPU 去完成这个压缩任务。而压缩文件这个过程本身是需要耗费时间的,可以理解为以服务器压缩的时间开销和 CPU 开销(以及浏览器解析压缩文件的开销)为代价,来节省一些传输过程中的时间开销。如果在构建的时候,直接将资源文件打包成 gz 压缩包,这样可以省去服务器压缩的时间,减少一些服务端的消耗。
使用 node 的 fs 模块去读取一个 gz 压缩包,可以看到如下一段 Buffer 内容:
1 | const fs = require("fs"); |
通常 gz 压缩包由文件头,文件体和文件尾三个部分构成。头尾专门用来存储一些文件相关信息,比如上面的 Buffer 数据,第一二个字节为1f 8b(16 进制),通常第一二字节为1f 8b就可以初步判断这是一个 gz 压缩包,但是具体还是要看是否完全符合 gz 文件格式,第三个字节取值范围是 0 到 8,目前只用 8,表示使用的是 Deflate 压缩算法。还有一些比如修改时间,压缩执行的文件系统等信息也会在文件头。而文件尾会标识出一些原始数据大小的相关信息,被压缩的数据则是放在中间的文件体。前面所说的,对于已经压缩过的图片,开启了 gzip 压缩反而可能会使其变得更大,就是因为中间实际压缩体没怎么减小,但是却添加了头尾的压缩相关信息。
Nginx 配置方式
1 | http { |
配置完成后在 response header 中可以查看。
Ⅱ. 压缩过程
用原生 node 写一个服务,目录和代码如下:

1 | const http = require("http"); |
用node server.js启动服务,此时我们访问 http://localhost:8080/vds.js,网页会显示 vds.js 文件的内容,查看 Network 面版,会发现 vds.js 请求大小是 88.73k,这便是原始资源文件的大小,Response Headers 中也没有 content-encoding: gzip ,说明这是未经过 gzip 压缩的。

如果要开启 gzip,只需要直接使用 node 提供的 zlib 模块,修改上面代码如下:
1 | const http = require("http"); |
运行这段代码,访问 http://localhost:8080/vds.js,会发现网页没有显示 vds.js 内容,而是直接下载了一个 vds.js 文件,大小是 25k,大小好像是经过了压缩的。但是如果尝试用编辑器打开这个文件,会发现打开失败或者提示这是一个二进制文件而不是文本。因为 gzip 就是一个压缩程序,将文件压缩进一个.gz 压缩包。将后缀名改为 gz,解压成功后会出来一个 88.73k 的 vds.js。

服务端在返回资源时,需要通过 Response Headers 里的 content-encoding: gzip告知浏览器这是一个 gz 压缩包,需要进行解压。
最后修改一下代码,加一个请求头:
1 | const http = require("http"); |
此时浏览器再请求到 gzip 压缩后的文件,会先解压处理一下再使用,这对于用户来说是无感知的。
Ⅲ. 压缩算法
gzip 中间的文件体,使用的是 Deflate 算法,这是一种无损压缩解压算法。Deflate 是 zip 压缩文件的默认算法,7z,xz 等其他的压缩文件中都有用到,实际上 deflate 只是一种压缩数据流的算法。任何需要流式压缩的地方都可以用。
Deflate 算法进行压缩时,一般先用 Lz77 算法压缩,再使用 Huffman 编码。
Lz77 算法的原理是,如果文件中有两块内容相同的话,我们可以用两者之间的距离,相同内容的长度这样一对信息,来替换后一块内容。由于两者之间的距离,相同内容的长度这一对信息的大小,小于被替换内容的大小,所以文件得到了压缩。
举个例子:
1 | http://www.baidu.com https://www.taobao.com |
上面一段文本可以看到,前后有部分内容是相同的,我们可以用前文相同内容的距离和相同字符长度替换后文的内容。
1 | http://www.baidu.com (21,12) taobao(23,4) |
Deflate 采用的 Lz77 算法是经过改进的版本,首先三个字节以上的重复串才进行偏码,否则不进行编码。其次匹配查找的时候用了哈希表,一个 head 数组记录最近匹配的位置和 prev 链表来记录哈希值冲突的之前的匹配位置。
② Brotli 压缩
Brotli 由 google 在 2015 年推出,用于网络字体的离线压缩,后发布包含通用无损数据压缩的 Brotli 增强版本,Brotli 基于 LZ77 算法的一个现代变体、Huffman 编码和二阶上下文建模。
与常见的通用压缩算法不同,Brotli 使用一个预定义的 120 千字节字典。该字典包含超过 13000 个常用单词、短语和其他子字符串,这些来自一个文本和 HTML 文档的大型语料库。预定义的算法可以提升较小文件的压缩密度。使用 brotli 取代 deflate 来对文本文件压缩通常可以增加 20% 的压缩密度,而压缩与解压缩速度则大致不变。
目前该压缩方式大部分浏览器(包括移动端)新版本支持良好,详细的支持情况可在caniuse查询到。
支持 Brotli 压缩算法的浏览器使用的内容编码类型为 br,例如以下是 Chrome 浏览器请求头里 Accept-Encoding 的值:
1 | Accept-Encoding: gzip, deflate, sdch, br |
如果服务端支持 Brotli 算法,则会返回以下的响应头:
1 | Content-Encoding: br |
brotli 压缩只能在 https 中生效,因为 在 http 请求中 request header 里的 Accept-Encoding: gzip, deflate 是没有 br 的。
目前该压缩方案的使用情况,去查看了几大网站的网络请求,国外的 google、Facebook、Bing 都已用上了 Brotli 压缩。国内的话淘宝,百度,腾讯,京东,b 站几个大站基本都没有使用,唯一发现使用了 brotli 压缩的是知乎。腾讯云,阿里云,又拍云这类的 CDN 加速服务商也都支持了 brotli 压缩。node 中没有原生模块支持 brotli 压缩,可以使用第三方库来支持,比如iltorb。
2. 图片优化
① 图片压缩
开发中比较重要的一个环节,我司自己的图床工具是自带压缩功能的,压缩后直接上传到 CDN 上。
如果公司没有图床工具,我们该如何压缩图片呢?我推荐几种我常用的方式
图片压缩是常用的手法,因为设备像素点的关系,UI 给予的图片一般都是 x2,x4 的,所以压缩就非常有必要。
② 图片分割
如果页面中有一张效果图,比如真机渲染图,压缩图片会导致展示效果不佳,这时可以考虑一下分割图片。建议单张图片的大小不要超过 100k,我们在分割完图片后,通过布局再拼接在一起,可以提高图片加载效率。分割后的每张图片一定要给 height,否则网速慢的情况下样式会塌陷。
③ 图片懒加载
懒加载也叫延迟加载,指的是在长网页中延迟加载图像,是一种优化网页性能的方式。图片懒加载在一些图片密集型的网站中运用比较多,它不会去加载当前不可视的图片,避免一次性加载过多图片导致请求阻塞(浏览器一般对同一域名下的并发请求的连接数有限制),这样就可以提高网站的加载速度,提高用户体验。
getBoundingClientRect()
① 首先需要给 html 中需要懒加载的 img 标签的src设置缩略图。或者不设置src,而是自定义一个属性,值为真正的图片地址(如下例 data-src),并定义一个类名,表示该图片是需要懒加载的(如下例的 lazy-image),这有两个作用:
- 为以后获取需要懒加载图片的 img 元素
- 可以给这个类名设置背景图片,作为图片未加载前的过度图片,比如显示为 loading 的图片。
1 |
|
② 页面加载完后,需要获取所有需要懒加载的图片集合,并判断是否在可视区域。如果处于可视区域,则设置元素的 src 属性值为真正图片的地址。
1 | inViewShow() { |
这里通过获取元素的getBoundingClientRect属性的top值和页面的clientHeight进行对比,来判断是否位于可视区域内。如果top值小于clientHeight,则说明元素出现在可视区域。BoundingClientRect是获取某个元素相对于视窗的位置集合,见下图,注意bottom和right和我们平时的right和bottom不一样。

第三步:当用户滚动窗口的时候,遍历所有需要懒加载的元素,通过每个元素的BoundingClientRect属性来判断元素是否出现在可视区域内,判断方法同第二步一样。这里可以通过函数节流优化滚动事件的处理函数。
1 | document.addEventListener('scroll', inViewShow) |
IntersectionObserver
上面利用元素的BoundingClientRect的top属性和 body 的clientHeight来判断元素是否可见,这种方式需要绑定 scroll 事件,但 scroll 事件是伴随着大量计算的,就算通过节流函数来提高性能,仍然会造成资源浪费。而高级特性IntersectionObserver可以不用监听 scroll 事件,一旦元素可见便执行回调函数,在回调函数里面再判断元素是否可见。
1 | // The IntersectionObserver interface of the Intersection Observer API provides a way to asynchronously observe changes in the intersection of a target element with an ancestor element or with a top-level document's viewport. The ancestor element or viewport is referred to as the root. |
完整代码
1 | class LazyImage { |
④ IconFont 代替图片
IconFont 就是字体图标。它就是一种字体,但不包含字母或数字,而是包含符号和字形。可以使用 CSS 对其设置样式,就像设置常规文本一样,这使得 IconFont 成为 Web 开发时图标的热门选择。
WebFont
在网页制作中会经常用到不同的字体,比如微软雅黑、宋体、Aria 等。在写 css 样式时,通过 font-family 可以指定元素的字体名称,我们称这类字体为 Web Font。但是传统 web 开发人员的可选字体是有限的。只有少数几种字体可以保证在所有公共系统中都能使用,即 Web-safe 字体。我们可以使用字体堆栈来先指定心仪的字体,其后是 Web-safe 的替代选项,最后是默认的系统字体,但为了确保我们的设计在每种字体中都能使用,这增加了测试的开销。
Web Font 是一种 CSS 特性,允许指定在访问时随网站一同下载的字体文件。首先,在 CSS 的开始处有一个@font-face 块,它指定要下载的字体文件:
1 | @font-face { |
然后就可以使用我们定义的字体了。
1 | html { |
IconFont
一个健全的网站少不了各种图标,添加图标的传统方式就是图片,但使用图片存在以下三处弊端:
- 增加了页面的请求
- 图片的大小和颜色不容易改变
- 为了调高清晰度,图片会越来越大
为了减少图片请求数,提高性能,我们可能会使用雪碧图:把网页中比较小的一些小图片整合到一张图片文件中,再利用 CSS 的 background-image 属性插入图片,然后利用 background-position 属性对图片所需要的部分进行精确定位。但是它有个问题就是,雪碧图比较适合固定功能的网站。如果我们的网站每隔一段时间就要加一些新功能,添加和替换雪碧图就变成了很繁琐的工作。
以上技术都有各种缺陷。在性能和方便性的需求上,IconFont 应运而生。IconFont 的使用方式和 WebFont 如出一辙,又把大量的图标变成了一个字体文件,减少了请求数,而且有效减小请求体积。当一个网页有自己的图标字体库之后,可以复用在很多地方,减少很多二次开发成本。因此现代网页多会使用 IconFont 来展示图标,那么如何使用并且生成 IconFont 也就变成了前端开发人员必知必会的能力。
优点
- 可以方便地将任何 CSS 效果应用于它们。
- 由于是矢量图形,所以它们是可伸缩的,容易修改。
- 只需要发送一个或少量 HTTP 请求来加载它们,而不必像图片可能需要多个 HTTP 请求。
- 由于轻量尺寸小,它们加载速度快。
- 它们在所有浏览器中都得到支持(甚至支持到 IE6)。
不足
- 不能用来显示复杂图像
- 通常只限于一种颜色,除非应用一些 CSS 技巧
- 字体图标通常是根据特定的网格设计的,例如 16x16, 32×32, 48×48 等。如果由于某种原因将网格系统改为 25×25,可能不会得到清晰的结果
原理
IconFont 的使用原理来自于 css 的 @font-face 属性。这个属性用来定义一个新的字体,基本用法如下
1 | @font-face { |
- font-family:为载入的字体取名字。
- src:[url]加载字体,可以是相对路径,可以是绝对路径,也可以是网络地址。[format]定义的字体的格式,用来帮助浏览器识别。主要取值为:【truetype(.ttf)、opentype(.otf)、truetype-aat、embedded-opentype(.eot)、svg(.svg)、woff(.woff)】。
- font-weight:定义加粗样式。
- font-style:定义字体样式。
format 对应字体格式,常见兼容性写法:
1 | @font-face { |
使用
IconFont 已经是比较成熟的技术了,国内比较常用的是 阿里妈妈 MUX,国外比较常用的有 Font-Awesome 和 Material Design(需要翻墙)。
关于 IconFont 的直接使用,教程非常多,这里列几篇笔者认为讲得不错的教程。
阿里 IconFont:
Font-Awesome:
Material Icons:
3. 资源预加载
Resource Hints(资源预加载) 是非常好的一种性能优化方法,可以大大降低页面加载时间,给用户更加流畅的用户体验。
现代浏览器使用大量预测优化技术来预测用户行为和意图,这些技术有预连接、资源与获取、资源预渲染等。
Resource Hints 的思路有如下两个:
- 当前将要获取资源的列表
- 通过当前页面或应用的状态、用户历史行为或 session 预测用户行为及必需的资源
实现 Resource Hints 的方法有很多种,可分为基于 link 标签的 DNS-prefetch、subresource、preload、prefetch、preconnect、prerender,和本地存储 localStorage。
preload 提供了一种声明,让浏览器提前加载指定资源(加载后暂不执行),在需要执行时再执行。提供的好处主要是
- 将加载和执行分离开,不阻塞渲染和 document 的 onload 事件
- 提前加载指定资源,依赖的 font 字体不会隔了一段时间才刷出
preload 将提升资源加载的优先级
使用 preload 前,在遇到资源依赖时才进行加载:
使用 preload 后,不管资源是否使用都将提前加载:
可以看到,preload 的资源加载顺序将被提前:
① preload 使用
link 标签创建
1 | <!-- 使用 link 标签静态标记需要预加载的资源 --> |
使用 HTTP 响应头的 Link 字段创建
1 | Link: <https://example.com/other/styles.css>; rel=preload; as=style |
如常用到的 antd 会依赖 CDN 上的一个 font.js 字体文件,我们可以设置为提前加载。以及有一些模块虽然是按需异步加载,但在某些场景下如果确定其必定会加载,则可以设置 preload 进行预加载,如:
1 | <link rel="preload" as="font" href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff"> |
如何判断浏览器是否支持 preload
目前支持 preload 的浏览器主要为高版本 Chrome,其他环境在 caniuse.com 上查到的支持情况如下:
在不支持 preload 的浏览器环境中,会忽略对应的 link 标签,而若需要做特征检测的话,则:
1 | const isPreloadSupported = () => { |
② preload VS prefetch
- preload 是告诉浏览器页面必定需要的资源,浏览器一定会加载这些资源;
- prefetch 是告诉浏览器页面可能需要的资源,浏览器不一定会加载这些资源。
preload 确认会加载指定资源,如 x-report.js 初始化后一定会加载 PcCommon.js 和 TabsPc.js, 则可以预先 preload 这些资源;prefetch 是预测会加载指定资源,如我们在页面加载后会初始化首屏组件,当用户滚动页面时,会拉取第二屏的组件,若能预测用户行为,则可以 prefetch 下一屏的组件。
③ 禁忌
避免滥用 preload
使用 preload 后,Chrome 会有一个警告:
如上文所言,若不确定资源是必定会加载的,则不要错误使用 preload,以免本末倒置,给页面带来更沉重的负担。
当然,可以在 PC 中使用 preload 来刷新资源的缓存,但在移动端则需要特别慎重,因为可能会浪费用户的带宽。
避免混用 preload 和 prefetch
preload 和 prefetch 混用的话,并不会复用资源,而是会重复加载。
1 | <link rel="preload" href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff" as="font"> |
使用 preload 和 prefetch 的逻辑可能不是写到一起,但一旦发生对同一资源 preload 或 prefetch 的话,会带来双倍的网络请求,这点通过 Chrome 控制台的网络面板就能甄别:
避免错用 preload 加载跨域资源
若 css 中有应用于已渲染到 DOM 树的元素的选择器,且设置了 @font-face 规则时,会触发字体文件的加载。而字体文件加载中时,DOM 中的这些元素,是处于不可见的状态。对已知必加载的 font 文件进行预加载,除了有性能提升外,更有体验优化的效果。
假设某场景中,antd.css 会依赖 font 文件,所以可以对这个字体文件进行 preload:
1 | <link rel="preload" as="font" href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff"> |
然而这个文件被加载了两次:
原因是对跨域的文件进行 preload 的时候,我们必须加上 crossorigin 属性:
1 | <link rel="preload" as="font" crossorigin href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff"> |
再看一下网络请求,就变成一条了。W3 规范是这么解释的:Preload links for CORS enabled resources, such as fonts or images with a cross-origin attribute, must also include a cross-origin attribute, in order for the resource to be properly used.
那为何会有两条请求,且优先级不一致,又没有命中缓存呢?这就得引出下一个话题来解释了。
④ 不同资源加载的优先级规则
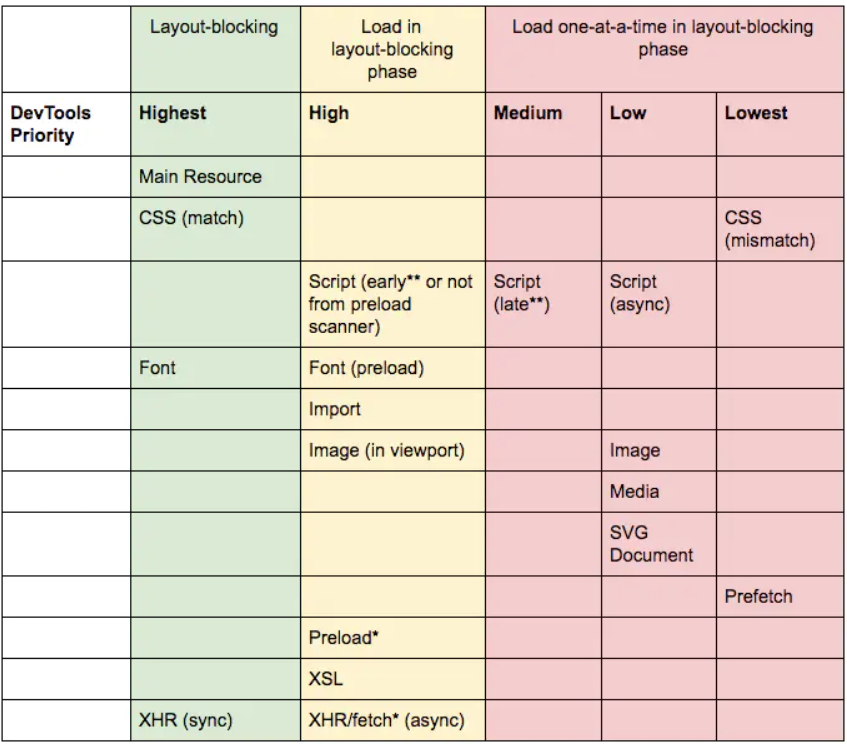
这张图表示在 Chrome 46 以后的版本中,不同资源在浏览器渲染的不同阶段进行加载的优先级。在这里只需要关注 Dev-Tools Priority 体现的优先级,一共分成五个级别:
- Highest 最高
- Hight 高
- Medium 中等
- Low 低
- Lowest 最低
html 主要资源,其优先级是最高的
css 样式资源,其优先级也是最高的
CSS(match) 指的是对已有的 DOM 具备规则的有效的样式文件。
script 脚本资源,优先级不一
前三个 js 文件是写死在 html 中的静态资源依赖,后三个 js 文件是根据首屏按需异步加载的组件资源依赖。
font 字体资源,优先级不一
css 样式文件中有一个 @font-face 依赖一个 font 文件,样式文件中依赖的字体文件加载的优先级是 Highest;在使用 preload 预加载这个 font 文件时,若不指定 cross-origin 属性 (即使同源),则会采用匿名模式的 CORS 去加载,优先级是 High,看下图对比:第一条 High 优先级也就是 preload 的请求:
第二条 Highest 也就是样式引入的请求:
可以看到,在 preload 的请求中,缺少了一个 origin 的请求头字段,表示这个请求是匿名的请求。让这两个请求能共用缓存的话,目前的解法是给 preload 加上 crossorigin 属性,这样请求头会带上 origin, 且与样式引入的请求同源,从而做到命中缓存:
1 | <link rel="preload" as="font" crossorigin href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff"> |
这么请求就只剩一个:
在网络瀑布流图中,也显示成功预加载且后续命中缓存不再二次加载:
(五)CSS 优化
1. content-visibility
一般来说,大多数 Web 应用都有复杂的 UI 元素,而且有的内容会在设备可视区域之外(内容超出了用户浏览器可视区域),比如下图中红色区域就在手机设备屏幕可视区域之外:

在这种场合下,可以使用 CSS 的新增属性content-visibility来跳过屏幕外的内容渲染。如果有大量的离屏内容(Off-screen Content),这将会大幅减少页面渲染时间。content-visibility的属性值有visible、auto和hidden,我们可以在一个元素上使用content-visibility:auto来直接提升页面的渲染性能。
假设有一个页面显示如下,整个页面有个卡片列表,卡片大约共 375 张,大约在屏幕可视区域能显示 12 张卡片。正如下图所示,渲染这个页面浏览器用时大约 1037ms:

可以给所有卡片添加content-visibility:
1 | .card { |
所有卡片加入content-visibility样式之后,页面的渲染时间下降到 150ms,提高了近六倍的渲染性能。

content-visibility属性能够影响浏览器的渲染过程,从本质上改变一个元素的可见性,并对其渲染状态进行管理。这类似于 CSS 的display和visibility属性,然而content-visibility的不同之处在于它允许推迟所选的 HTML 元素渲染。
浏览器默认会渲染 DOM 树内所有能被用户查看的元素。用户可以看到视窗可视区域中所有元素,并通过滚动查看页面内其他元素。一次渲染所有元素(包括视窗可视区域外的 HTML 元素)可以让浏览器正确计算页面的尺寸,同时保持整个页面的布局和滚动条的一致性。
而content-visibility会将对应元素的高度(height)视为0,浏览器便在渲染前将这个元素的高度变为0,从而无法正确计算页面高度,导致滚动变得混乱。可以通过给元素或其子元素显式设置高度,来覆盖这种行为。但显式设置height可能会带来副作用,这里建议使用contain-intrinsic-size来确保元素的正确渲染,同时保留延迟渲染的好处。
1 | .card { |
这意味着它好像拥有一个固定尺寸(Intrinsic-size)的单一子元素,确保没有设置尺寸的div(示例中的.card)仍然占据空间。contain-intrinsic-size作为一个占位符尺寸来替代渲染内容。虽然contain-intrinsic-size能让元素拥有占位空间,但如果有大量的元素都设置了content-visibility: auto,滚动条仍然会有较小的问题。另外两个属性visible和hidden可以实现像元素的显示和隐藏,类似于display的none和非none值的切换。

在这种情况下,content-visibility可以提高需要频繁显示或隐藏的元素的渲染性能,例如模态框的显示和隐藏,这要归功于其隐藏值(hidden)的功能与其他值的不同:
display: none:隐藏元素并破坏其渲染状态。这意味着取消隐藏元素与渲染具有相同内容的新元素一样昂贵visibility: hidden:隐藏元素并保持其渲染状态。这并不能真正从文档中删除该元素,因为它(及其子树)仍占据页面上的几何空间,并且仍然可以单击。它也可以在需要时随时更新渲染状态,即使隐藏也是如此content-visibility: hidden:隐藏元素并保留其渲染状态。这意味着该元素隐藏时行为和display: none一样,但再次显示它的成本要低得多
content-visibility属性的扩展阅读:
content-visibility: the new CSS property that boosts your rendering performance- More on
content-visibility
3. contain
contain属性能使特定的 DOM 元素及其子元素独立于整个 DOM 树结构之外,这样浏览器就可以只对部分元素进行重绘、重排,而不必每次针对整个页面。即 contain 允许浏览器针对 DOM 的有限区域而非整个页面重新计算布局样式等。
在实际使用时,可以通过对contain设置如下属性值来规定元素以何种方式独立于文档树。contain的size、layout和paint提供了不同的方式来影响浏览器渲染计算:
layout:元素的内部布局不受外部的任何影响,同时该元素以及其内容也不会影响到上级。向浏览器告知容器的后代不应该导致其容器外元素的布局改变,反之亦然;paint:元素的子级不能在该元素的范围外显示,该元素不会有任何内容溢出(即使溢出也不会被显示)。向浏览器告知容器的内容将永远不会绘制超出容器的尺寸,如果容器是模糊的,那么就根本不会绘制内容;size:元素盒子的大小独立于其内容,即在计算该元素盒子大小时会忽略其子元素。告诉浏览器当其内容发生变化时,该容器不应导致页面上的位置移动;content:该值是contain: layout paint的简写;strict:该值是contain: layout paint size的简写。
size、layout和paint可以单独使用,也可以组合使用;另外content和strict是组合值,即content是layout paint的组合,strict是layout paint size的组合。
@Manuel Rego Casasnovas 提供了一个示例,向大家阐述和演示了contain是如何提高 Web 页面渲染性能。这个示例中,有10000个像下面这样的 DOM 元素:
1 | <div class="item"> |
使用 JavaScript 的textContent这个 API 来动态更改div.item > div的内容:
1 | const NUM_ITEMS = 10000; |
如果不使用contain,即使是在单个元素上更改,浏览器在布局上也会花费大量时间渲染,因为它会遍历整个 DOM 树(在本例中,DOM 树很大,因为它有10000个 DOM 元素):

在本例中,div的大小是固定的,就算在内部div中更改内容也不会导致溢出。因此可以将contain: strict应用到项目上,这样当项目内部发生变化时,浏览器就不用访问其他节点,它可以停止检查该元素上的内容,并避免到外部去。
通过使用contain,Web 性能从~4ms降到了~0.04ms,这是一个巨大的提升。
有关于contain的更多内容:
- Let’s Take a Deep Dive Into the CSS Contain Property
- Helping Browsers Optimize With The CSS Contain Property
- CSS
containProperty
4. font-display
在 Web 开发过程中,难免会使用@font-face技术引用一些系统没有的特殊字体,同时也可能会配合变量字体特性,使用更具个性化的字体。使用@font-face加载字体策略大概如下图所示:

网站加载自定义字体(@font-face规则引入的字体)需要一段时间。在加载自定义字体时,一些浏览器会隐藏文字,这种称之为 FOIT(Flash Of Invisible Text),而另一些浏览器会显示降级字体,这种情况称之为 FOUT(Flash Of Unstyled Text)。这很容易导致字体闪烁,整个排版布局也会发生偏移,影响视觉稳定性(CLS, Cumulative Layout Shift,累计布局偏移)。幸好,根据@font-face规则,font-display属性定义了浏览器如何加载和显示字体文件,允许文本在字体加载失败时显示回退字体。可以通过依靠折中无样式文本闪现使文本可见,替代白屏来提高性能。
CSS 的font-display属性有五个不同的值:
auto:默认值。典型的浏览器字体加载的行为会发生,即使用自定义字体的文本会先被隐藏,直到字体加载结束才会显示。当前,大多数浏览器的默认策略类似blockblock:给予字体一个较短的阻塞时间(大多数情况下推荐使用3s)和无限大的交换时间。即如果字体未加载完成,浏览器将首先绘制“隐形”文本;一旦字体加载完成,立即切换字体。为此,浏览器将创建一个匿名字体,其类型与所选字体相似,但所有字形都不含“墨水”。使用特定字体渲染文本后页面方才可用,只有这种情况下才应该使用block。swap:使用swap,则阻塞阶段时间为0,交换阶段时间无限大。也就是说,如果字体没有完成加载,浏览器会立即绘制文字,一旦字体加载成功,立即切换字体。与 block 类似,如果使用特定字体渲染文本对页面很重要,且使用其他字体渲染仍将显示正确的信息,才应使用swap。fallback:这个可以说是auto和swap的一种折中方式。需要使用自定义字体渲染的文本会在较短的时间不可见,如果自定义字体还没有加载结束,那么就先加载无样式的文本。一旦自定义字体加载结束,那么文本就会被正确赋予样式。使用fallback时,阻塞阶段时间将非常小(多数情况下推荐小于100ms),交换阶段也比较短(多数情况下建议使用3s)。换言之,如果字体没有加载,则首先会使用后备字体渲染。一旦加载成功,就会切换字体。但如果等待时间过久,则页面将一直使用后备字体。如果希望用户尽快开始阅读,而且不因新字体的载入导致文本样式发生变动而干扰用户体验,fallback是一个很好的选择。optional:效果和fallback几乎一样,都是先在极短的时间内文本不可见,然后再加载无样式的文本。不过optional选项可以让浏览器自由决定是否使用自定义字体,而这个决定很大程度上取决于浏览器的连接速度。如果速度很慢,那你的自定义字体可能就不会被使用。使用optional时,阻塞阶段时间会非常小(多数情况下建议低于100ms),交换阶段时间为0。
下面是使用swap值的一个例子:
1 | @font-face { |
在这个例子里只使用WOFF2文件来缩写字体。另外我们使用了swap作为font-display的值,页面的加载情况将如下图所示:
注意,
font-display一般放在@font-face规则中使用。
有关于字体加载和font-display更多的介绍,可以阅读:
- A deep dive into webfonts
- How to avoid layout shifts caused by web fonts
- The Best Font Loading Strategies and How to Execute Them
- A font-display setting for slow connections
- How to Load Fonts in a Way That Fights FOUT and Makes Lighthouse Happy
- The importance of
@font-facesource order when used with preload - The Fastest Google Fonts
- A COMPREHENSIVE GUIDE TO FONT LOADING STRATEGIES
5. scroll-behavior
scroll-behavior可以轻易实现丝滑的滚动效果。该属性可以为一个滚动框指定滚动行为,而其他任何滚动,例如由于用户行为而产生的滚动,不受该属性影响。scroll-behavior接受两个关键字值:
auto:滚动框立即滚动。The scrolling box scrolls instantly.smooth:滚动框通过一个用户代理定义的时间段使用定义的时间函数来实现平稳的滚动,用户代理平台应遵循约定,如果有的话。The scrolling box scrolls in a smooth fashion using a user-agent-defined timing function over a user-agent-defined period of time. User agents should follow platform conventions, if any.
除此之外,还有三个全局值:inherit、initial和unset。只需要在指定元素上使用scroll-behavior:smooth,就可以让页面滚动更平滑,建议在html中直接这样设置样式:
1 | html { |
效果对比如下:
有关于scroll-behavior属性更多的介绍可以再花点时间阅读下面这些文章:
- CSSOM View Module:
scroll-behavior - CSS-Tricks:
scroll-behavior - Native Smooth Scroll behavior
- PAGE SCROLLING IN VANILLA JAVASCRIPT
- smooth scroll behavior polyfill
7. 减少渲染阻止时间
今天,许多 Web 应用必须满足多种形式的需求,包括 PC、平板电脑和手机等。为了完成这种响应式的特性,必须根据媒体尺寸编写新的样式。当涉及页面渲染时,它无法启动渲染阶段,直到 CSS 对象模型(CSSOM)已准备就绪。根据你的 Web 应用,你可能会有一个大的样式表来满足所有设备的形式因素。
但是,假设我们根据表单因素将其拆分为多个样式表。在这种情况下,我们可以只让主 CSS 文件阻塞关键路径,并以高优先级下载它,而让其他样式表以低优先级方式下载。
1 | <link rel="stylesheet" href="styles.css"> |
将其分解为多个样式表后:
1 | <!-- style.css contains only the minimal styles needed for the page rendering --> |
默认情况下,浏览器假设每个指定的样式表都是阻塞渲染的。通过添加 media属性附加媒体查询,告诉浏览器何时应用样式表。当浏览器看到一个它知道只会用于特定场景的样式表时,它仍会下载样式,但不会阻塞渲染。通过将 CSS 分成多个文件,主要的阻塞渲染文件(本例中为 styles.css)的大小变得更小,从而减少了渲染被阻塞的时间。
8. 避免@import 嵌套样式表
通过 @import可以在一个样式表中包含另一个样式表。当我们在处理一个大型项目时,使用 @import 可以使代码更加简洁。 @import 是一个阻塞调用,因为它必须通过网络请求来获取和解析文件,并将其包含在样式表中。如果我们在样式表中嵌套了 @import,就会妨碍渲染性能。
1 | /* style.css */ |
与使用 @import 相比,我们可以通过多个 link 来实现同样的功能,但性能要好得多,因为它允许我们并行加载样式表。
link 和@import的区别
- link 属于 XHTML 标签,而
@import是 CSS 提供的。页面被加载时,link 会同时被加载,而@import引用的 CSS 会等到页面被加载完再加载。 - import 只在 IE5 以上才能识别,而 link 是 XHTML 标签,无兼容问题。
- link 的样式权重高于
@import的权重。 - 当使用 javascript 控制 dom 去改变样式的时候,只能使用 link 标签,因为
@import不是 dom 可以控制的。
9. 修改自定义属性方式
CSS 自定义属性又名 CSS 变量,该特性已经是非常成熟的特性了,可以在 Web 的开发中大胆的使用该特性:
1 | :root { --color: red; } |
在使用 CSS 自定义属性时,时常在root(根元素)上注册自定义属性,这种方式注册的自定义属性是全局的,可以被所有嵌套的子元素继承。就上例而言,--color属性允许任何button样式将其作为变量使用。可以使用style.setProperty来重新设置已注册好的自定义属性的值。但在修改根自定义属性时,为了避免影响 Web 性能,需要注意以下几点:
- 在使用 CSS 变量时,应当注意变量是在哪个范围内定义的,改变它可能会影响许多子代,从而造成大量样式重新计算;
- 结合 CSS 变量使用
calc()可以获得更多的灵活性,限制我们需要定义的变量数量。在大多数浏览器中calc()与 CSS 变量的结合不会带来任何大的性能问题。然而在某些浏览器中对一些单位的支持有限,比如deg或ms; - 在 JavaScript 中通过内联样式设置变量与通过
setProperty设置变量,在不同浏览器间存在一些差异。在 Safari 中通过内联样式设置属性的速度非常快,而在 Firefox 中则非常慢。
(六)JS 优化
JavaScript 是单线程运行的,即在 JavaScript 运行一段代码块的时候,页面中其他的事情(UI 更新或者别的脚本加载执行等)在同一时间段内是被挂起的状态,不能被同时处理,所以在执行一段 js 脚本时,这段代码会影响其他的操作。JavaScript 的这一特性叫做阻塞特性,正因如此,在对 JavaScript 的性能优化上变得相对复杂。
最初设计 JavaScript 的目的只是用来在浏览器端改善网页的用户体验,去处理一些页面中类似表单验证的简单任务。所以当时 JavaScript 所做的事情很少,并且代码量很少,这也奠定了 JavaScript 和界面操作的强关联性。既然 JavaScript 和界面操作强相关,假如 JavaScript 采用了多线程的处理方式,那么当某个页面中有两段 js 脚本都去更改某个 dom 元素内容时,就无法确定最终是哪段 JS 脚本操作了该页面元素显示的内容,因为两段 js 是通过不同线程加载的,我们无法预估谁先处理完,这并非我们想要的结果,而这种界面数据更新的操作在 JavaScript 中比比皆是。因此 JavaScript 采用单线程,就是为了避免在执行过程中页面内容被不可预知地重复修改。
1. 减少请求次数
页面加载的过程中,最耗时间的不是 js 本身的加载和执行,而是 Http 三次握手过程。因此,减少 HTTP 请求是需要着重优化的一项,事实上,在页面中 js 脚本文件加载很多的情况下,它的优化效果是很显著的。
① JS 精简与压缩
减少传递的 JavaScript 数量意味着减少网络传输时间、解压缩代码的成本以及花费在解析和编译 JavaScript 上的时间。精简文件实际并不复杂,但不当的使用也会导致代码无效或错误,因此最好在压缩前对 js 进行语法解析,避免不必要的问题(例如文件中包含中文等 unicode 转码问题)。
常用的解析型压缩工具有:YUI Compressor、Closure Complier、UglifyJs
- YUI Compressor:YUI Compressor 的出现曾被认为是最受欢迎的基于解析器的压缩工具,它将去除代码中的注释和额外空格并且会用单个或两个字符去代替局部变量以节省更多字节。但默认会关闭对可能导致错误的替换,例如 with 或者 eval();
- Closure Complier:Closure Complier 同样是一个基于解析器的压缩工具,他会试图去让你的代码变得尽可能小。它会去除注释和额外的空格并进行变量替换,而且会分析你的代码进行相应的优化,比如他会删除你定义了但未使用的变量,也会把只使用了一次的变量变成内联函数。
- UglifyJs:UglifyJs 被认为第一个基于 node.js 的压缩工具,它会去除注释和额外的空格,替换变量名,合并 var 表达式,也会进行一些其他方式的优化
每种工具都有自己的优势,比如说 YUI 压缩后的代码准确无误,Closure 压缩的代码会更小,而 UglifyJs 不依靠于 Java 而是基于 JavaScript,相比 Closure 错误更少,具体用哪个更好没有确切的答案,开发者应该根据自己项目实际情况酌情选择。
② node middleware
中间件主要是指封装所有 Http 请求细节处理的方法。一次 Http 请求通常包含很多工作,如记录日志、ip 过滤、查询字符串、请求体解析、Cookie 处理、权限验证、参数验证、异常处理等,但对于 Web 应用而言,并不希望接触到这么多细节性的处理,因此引入中间件来简化和隔离这些基础设施与业务逻辑之间的细节,让我们能够关注在业务的开发上,以达到提升开发效率的目的。
使用 node middleware 合并请求。减少请求次数。这种方式也是非常实用的。
2. 延迟脚本加载
① 合理放置脚本位置
由于 JavaScript 的阻塞特性,在每一个<script>出现时,无论是内嵌还是外链方式,页面都会等待该脚本的加载解析和执行,并且<script>标签可以放在页面的<head>或<body>中,因此如果页面中的 css 和 js 的引用顺序或者位置不一样,即使是同样的代码,加载体验都是不一样的。
1 |
|
以上代码是一个简单的 html 界面,其中加载了两个 js 脚本文件和一个 css 样式文件,由于 js 的阻塞问题,当加载到 index-1.js 时,其后的代码将会被挂起等待,直到其加载执行完毕,才会去执行第二个脚本文件 index-2.js,这时页面又将被挂起等待脚本的加载和执行完成,依此类推,这样用户打开该界面时,界面内容会明显被延迟,这会导致一个空白的页面闪过,用户体验不好,因此应尽量让内容和样式先展示出来,将<script>脚本放在<body>最后,以此来优化用户体验。
1 |
|
② 无阻塞脚本加载
现在的 web 应用功能丰富,js 脚本越来越多,光靠精简源码大小和减少访问次数不总是可行的。即使只有一次 HTTP 请求,但如果文件过于庞大,界面也会被长时间锁死。因此,无阻塞加载技术应运而生。简单来说,就是在页面加载完成后才异步加载 js 代码,即在 window 对象的 load 事件触发后才去下载脚本。要实现这种延迟脚本加载,常用以下两种方式:
defer
HTML4 以后为<script>标签定义了一个扩展属性:defer。defer 属性的作用是指明要加载的这段脚本不会修改 DOM,因此代码是可以安全的去延迟执行的,并且现在主流浏览器已经全部对 defer 支持。
1 | <script type="text/javascript" src="index-1.js" defer></script> |
带 defer 属性的<script>标签在 DOM 完成加载前都不会执行,无论是内嵌还是外链方式。
async
HTML5 规范中也引入了 async 属性,用于异步加载脚本,其作用大致和 defer 一样,都采用并行下载,下载过程中不会有阻塞,但不同点是 async 在加载完成后就会自动执行代码,阻塞主线程,影响 DOM 解析,但 defer 会在页面加载完成后才执行。
③ 动态添加脚本
动态添加脚本的好处在于,无论这段脚本在何时启动下载,甚至直接将其添加到头部 head 标签中,它的下载和执行过程都不会阻塞页面的其他进程。
1 | var script = document.createElement('script'); |
如上便是动态创建<script>的方式。浏览器通过这种方式下载脚本文件后,会等到所有动态节点加载完毕后再执行这段脚本。这种情况下,为了确保当前脚本中包含的其它脚本的接口或方法能够被成功调用,就必须在别的脚本加载前完成这段代码的准备。解决的具体操作思路是:
浏览器将<script>下载完成后会接收一个 load 事件,可以在 load 事件中再去执行我们想要执行的代码,在 IE 中则会接收 loaded 和 complete 事件,理论上是 loaded 完成后才会有 completed,但实践似乎并无先后,甚至有时只会拿到其中一个事件,我们可以单独封装一个专门的函数来体现这个功能的实践性,因此统一的写法是:
1 | function LoadScript(url, callback) { |
Load-Script 函数接收两个参数,分别是要加载的脚本路径和加载成功后需要执行的回调函数,Load-Script 函数根据检测结果(IE 和其他浏览器),来决定脚本处理过程中监听哪一个事件。实际上这里的 Load-Script() 函数,就是 LazyLoad.js(懒加载)的原型。有了这个方法,我们可以实现一个简单的多文件按某一固定顺序加载代码块:
1 | LoadScript('file-1.js', function(){ |
以上代码执行时,会首先加载 file-1.js,加载完成后再去加载 file-2.js,以此类推。当然这种写法会导致回调地狱,但可以借此一窥动态脚本添加的思想和加载过程中需要注意和避免的问题。如果文件过多,并且加载的顺序有要求,最好的解决方法还是按照正确的顺序合并一起加载,这从各方面讲都是更好的法子。
3. 代码分割
代码分割(Code Splitting)是指,将脚本中无需立即调用的代码在代码构建时转变为异步加载的过程。在 Webpack 构建时,会避免加载已声明要异步加载的代码,异步代码会被单独分离成一个文件,当代码实际调用时被加载至页面。
代码分割技术的核心原理是异步加载资源。W3C stage 3 规范里,声明了可以通过 import() 关键字让浏览器在程序执行时异步加载相关资源。

如上图所示,IE 浏览器目前并不支持这一特性,但这并不意味着异步加载功能会在 IE 浏览器失效,实际上 Webpack 底层会将异步加载的代码抽离成一份新的文件,并在你需要时通过 JSONP 的方式去获取文件资源,因此可以在任何浏览器上实现代码的异步加载,并且在将来所有浏览器都实现 import() 方法时平滑过渡。
代码分割可以分为静态分割和动态分割两种方式,但动态分割并不是指异步调用的代码是动态生成的。
① 静态代码分割
静态代码分割是指在代码中明确声明需要异步加载的代码。
下示代码说明了应如何使用这一技术:每当调用一个声明了异步加载代码的变量时,它总是返回一个 Promise 对象。
1 | import Listener from './listeners.js' |
在 Vue 中可以直接使用 import() 关键字做到这一点,而在 React 中需要使用 react-loadable 去完成同样的事。
静态代码分割技术适合用在以下的场景:
当使用一个非常大的库或框架时,如果在页面初始化时不需要使用它,可以对其异步加载;
任何临时性资源(不在页面初始化时被使用,被使用后又会立即被销毁的资源),例如模态框、对话框、tooltip 等。任何一开始不显示在页面上的东西都可以有条件的加载;
路由:既然用户不会一下子看到所有页面,那么最好只把当前页面相关资源给用户;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import Vue from "vue";
import VueRouter from "vue-router";
// 对路由进行懒加载
const Home = () => import("views/home/Home.vue");
const Category = () => import("views/category/Category.vue");
const Cart = () => import("views/cart/Cart.vue");
const Profile = () => import("views/profile/Profile.vue");
const Detail = () => import("views/detail/Detail.vue");
// 1.安装 vuerouter 插件
Vue.use(VueRouter);
const routes = [
{
path: "",
redirect: "/home",
},
{
path: "/category",
component: Category,
},
{
path: "/home",
component: Home,
},
{
path: "/cart",
component: Cart,
},
{
path: "/profile",
component: Profile,
},
{
path: "/detail/:iid",
component: Detail,
},
];
// 2.创建 router
const router = new VueRouter({
routes,
mode: "history",
});
export default router;② 动态代码分割
动态代码分割是指在代码调用时根据当前的状态,动态地异步加载对应的代码块。
下示代码说明了它具体是如何被实现的:
1 | const getTheme = (themeName) => import(`./src/themes/${themeName}`) |
如上实现了动态声明所要异步加载的代码块,这得益于 Webpack 会在构建时将声明的目录下的所有可能分离的代码都抽象为一个文件(即 context Module 模块),因此无论最终声明调用哪个文件,本质上就和静态代码分割一样,在请求一个早已准备好的静态文件。也就是说,可以用静态代码分割代替「动态」代码分割,但后者比前者拥有更少的代码量。
使用动态代码分割技术的一些场景如下:
- A/B Test:不需要在代码中引入非必要的 UI 代码;
- 加载主题:根据用户的设置,动态加载相应的主题。
③ 魔术注释
魔术注释是由 Webpack 提供的,可以为代码分割服务的一种技术。通过在 import 关键字后的括号中使用指定注释,我们可以对代码分割后的 chunk 有更多的控制权,示例如下:
Webpack Chunk Name
1 | // index.jsimport ( /* webpackChunkName: “my-chunk-name” */ './footer') |
同时,也要在 webpack.config.js 中做一些改动:
1 | // webpack.config.js{ output: { filename: “bundle.js”, chunkFilename: “[name].lazy-chunk.js” }} |
通过这样的配置,我们可以对分离出的 chunk 进行命名,这对于我们 debug 而言非常方便。
4. 逻辑后移
逻辑后移是一种比较常见的优化手段。以打开一新闻网站举例,没有进行逻辑后移处理的请求顺序可能如下:

页面的展示主体应是文章,如果文章展示的请求被靠后,那么渲染文章出来的时间必然靠后。而且如果发生请求阻塞,影响到请求响应情况,会更加慢。很明显应该把主体“请求文章”接口前移,把一些非主体的请求逻辑后移。这样就可以尽快把主体渲染出来,优化后的顺序如下:

在平常的开发中建议时常注意逻辑后移的情况,突出主体逻辑。可以极大提升用户体验。
(七)DOM 优化
1. 避免频繁读写 DOM 元素
访问 DOM 的次数越多,代价也就越高。
① 减少读 DOM 次数
缓存 DOM 引用
获取 DOM 后请将引用缓存,不要重复获取。jQuery 的链式调用虽然方便获取,但有时会让人跌入忽视缓存 DOM 的陷阱。
1 | var render = (function() { |
缓存 DOM 的属性
思路同上,如果已知变化的属性,可以将其缓存在内存,然后将元素变化后的值放在缓存中,避免使用 DOM 属性进行存储。这样可以减少很多不必要的 DOM 读取操作,特别是某些属性还会引发浏览器回流(这些属性下文会提及)。这在用 JavaScript 控制一些物体位置变化的时候比较容易忽略。jQuery 时代,人们习惯于将数据保存在 DOM 元素上,殊不知这将引发性能问题,我曾今就犯过类似的错误,导致一个移动端上的赛车游戏性能低下。
1 | // bad |
缓存 HTMLCollection 的 length
HTMLCollection 根据页面的情况动态更新,如果更新了页面,那么它的内容也会发生变化,下面的代码会是无限循环。
1 | var divs = document.getElementsByTagName("div") ; |
② 避免循环操作 DOM 元素
循环中操作 DOM,每次循环都会产生一次读操作与写操作,所以我们的优化思路是将循环结果缓存起来,循环结束后统一操作能节省很多读写操作。
合并多次写操作
1 | // bad |
使用 documentFragment
另外 documentFragment 也可达到这样的目的,因为文档片段存在于内存中,并不在 DOM 树中,所以将子元素插入到文档片段时不会引起页面回流。因此,使用文档片段 document fragments 通常会起到优化性能的作用。
1 | var fragment = document.createDocumentFragment(); |
至于上文中 innerHTML 与 fragment 谁更快,请看这里,有此文还引申出新的优化规则:优先使用 innerHTML(甚至是更好地 insertAdjacentHTML) 与 fragment。
2. CSS 避免重排重绘
如何减少重排和重绘
- 尽量避免
style的使用,对于需要操作DOM元素节点,重新命名className,更改className名称。 - 如果增加元素或
clone元素,可以先把元素通过documentFragment放入内存中,等操作完毕后再appendChild到DOM元素中。 - 不要经常获取同一个元素,可以第一次获取元素后,用变量保存下来,减少遍历时间。
- 尽量使用
visibility:hidden代替dispaly:none,dispaly:none会造成重排,visibility:hidden会造成重绘。 - 不要使用
Table布局,因为一个小小的操作,可能就会造成整个表格的重排或重绘。 - 使用
resize事件时,做防抖和节流处理。 - 对动画元素使用
absolute / fixed属性。 - 批量修改元素时,可以先让元素脱离文档流,等修改完毕后,再放入文档流。
① 开启 GPU 渲染动画
虽然浏览器是单线程执行 js 代码,但实际上浏览器并非只有一个线程,而是主线程和合成线程协同工作来渲染一个网页。
- 主线程:运行 JavaScript;计算 CSS 样式;布局页面;将元素绘制到位图中;将这些位图交给合成线程。
- 合成线程:通过 GPU 将位图绘制到屏幕上;通知主线程更新页面中可见或即将变成可见的部分的位图;计算出页面中哪部分可见以及在滚动页面时哪部分即将变成可见;当滚动页面时将相应位置的元素移动到可视区域。
长时间执行 JavaScript 或渲染一个很大的元素会阻塞主线程,在这期间,它将无法响应用户的交互。而合成线程则会尽量去响应用户的交互。当一个页面发生变化时,合成线程会以每秒 60 帧的间隔去不断重绘这个页面,即使这个页面不完整。例如,当用户滚动页面时,合成线程会通知主线程更新页面中最新可见部分的位图。但如果主线程响应得不够快,合成线程并不会保持等待,而是马上绘制已经生成的位图,还没准备好的部分用白色进行填充。
以下 CSS 属性可以避免让主线程进行频繁操作,从而提升动画性能。
css3 动画卡顿的解决方案总结:
就算不想对元素应用 3D 变换,也一样可以开启 3D 引擎。例如可以用 transform: translateZ(0) 来开启 GPU 加速。只对我们需要实现动画效果的元素应用以上方法,如果仅仅为了开启硬件加速而随便乱用,那是不合理的。
Ⅰ. transform
在使用 transition 做动画效果时,优先选择 transform,尽量不要使用 height,width,margin 和 padding。transform 提供了丰富的 API,例如 scale,translate,rotate 等,在使用时需要考虑兼容性。对于大多数 css3 来说,mobile 端支持性较好,desktop 端支持性需要留意。
假设要将一个元素的 margin-left 从 100 px 变成 200 px,动画过渡采用 transition: margin-left,就像这样:
1 | div { |
在使用 height、width、margin 和 padding 等作为 transition 的值时,每一帧中元素的内容都在不断改变,所以主线程必须不断计算布局并生成该元素的位图。上例中从 margin-left: 20px,19px,一直到 0px,每一帧中主线程都必须经过执行脚本 Scripts、生成 Render Tree、Layout 和 Paint 四个阶段的计算,以及将新生成的位图提交给 GPU。然后合成线程通过 GPU 再绘制渲染到屏幕上。前后总共进行 20 次主线程渲染,20 次合成线程渲染,总计 40 次计算。
如果改用 transition: transform,主线程只进行一次计算,合成线程会依次将 -20px 转换到 0px,这样仅计算 21 次。
1 | div { |
transform 属性不会更改元素和其周围元素的布局,而会对元素的整体产生影响(对整个元素进行缩放、旋转、移动处理),这样浏览器只需生成一次该元素的位图,并在动画开始时将它提交给 GPU 去处理。之后浏览器不需要再做布局绘制和提交位图的操作,从而浏览器可以充分利用 GPU 的特长去快速地将位图绘制在不同的位置、执行旋转或缩放处理。
Ⅱ. opacity 优化阴影动画
项目中常要实现伴随阴影的动画,一般都会用到box-shadow ,举例如下:
1 | div { |
因为过渡动画是在两个不同的盒阴影状态下发生,所以在过渡时间内浏览器会不断重绘盒阴影。而又由于阴影属于耗性能样式,这种动画容易产生卡顿。我们可以使用伪元素及透明度对其进行优化:给元素添加一个 before 伪元素,大小与父 div 一致,并且提前给这个元素添加好所需要的最终的盒阴影状态,但是元素的透明度为 0。
1 | div { |
然后在 hover 时,我们只需要将伪元素的透明度从 0 设置为 1 即可。
1 | div:hover::before { |
这样做的好处是,实际在进行的阴影变化,其实只是透明度的变化,而没有对阴影进行不断的重绘,从而有效提升了阴影动画的流畅程度,让它看起来更加丝滑。
之所以要对透明度 opacity 而非box-shadow进行 transition 过渡,是因为后者的变换对页面重排重绘的影响更大。

Demo 可以看Code Pen Demo – 优化 box-shadow 动画
上述这个方案其实不算完美,因为最终的效果是两个阴影的叠加效果,可能整体上阴影颜色更深。所以需要对最终状态的阴影进行微调一下,削弱一点效果,尽量让两个阴影的叠加效果与单一阴影效果相近。我们可以再使用一个 ::after 伪元素,::after 伪元素设置为初始状态且透明度为 1,::before 伪元素设置为末尾状态且透明度为 0:
1 | div { |
实际 hover 时,对两个伪元素进行一显一隐,这样最终的效果只有一个阴影效果,没有阴影的叠加,与直接对阴影进行过渡变化效果一致:
1 | div:hover::before { |
Ⅲ. filter
Ⅳ. 固定定位
Ⅴ. will-change
CSS 渲染器(CSS Renderer)在渲染样式前对一些 CSS 属性需要一个准备过程,这容易导致页面出现卡顿,给用户带来不好的体验。比如 Web 上的动效,Web 动画(在动的元素)通常是和其他元素一起定期渲染的,以往在动画开发时会使用 CSS 的 3D 变换(transform中的translate3d()或translateZ())来开启 GPU 加速,让动画变得更流畅,这其实是一种黑魔法,会将元素和它的上下文提升到另一个层,独立于其他元素被渲染。然而这会将元素提取到一个新层,相对来说代价也是昂贵的,可能会使transform动画延迟几百毫秒。
现在可以不用transform这样的 Hack 手段来开启 GPU 加速,而直接使用 CSS 的will-change属性,该属性表明元素将修改特定的属性,让浏览器能事先进行必要优化。即will-change是一个 UA 提示,它不会对元素产生任何样式上的影响。注意,如果创建了新的层叠上下文,它可以产生外观效果。
比如下面这样的一个动画示例:
1 | <!-- HTML --> |
浏览器渲染上面的代码时,会为该元素创建一个单独的层,然后将该元素的渲染与其他优化一起委托给 GPU。即浏览器会识别will-change属性,并优化未来与 opacity 相关的变化,这将使动画变得更加流畅,因为 GPU 加速接管了动画的渲染。
根据 @Maximillian Laumeister 所做的性能基准,可以看到,他通过这种单行变化获得了超过
120FPS的渲染速度,和最初的渲染速度(大约50FPS)相比,提高70FPS左右。
will-change的使用并不复杂,它能接受的值有:
auto:默认值,浏览器会根据具体情况,自行进行优化scroll-position:表示开发者将要改变元素的滚动位置,比如浏览器通常仅渲染可滚动元素“滚动窗口”中的内容。而某些内容超过该窗口(不在浏览器的可视区域内)。如果will-change显式设置了该值,将扩展渲染“滚动窗口”周围的内容,从而顺利地进行更长,更快的滚动(让元素的滚动更流畅)content:表示开发者将要改变元素的内容,比如浏览器常将大部分不经常改变的元素缓存下来。但如果一个元素的内容不断发生改变,那么产生和维护这个缓存就是在浪费时间。如果will-change显式设置了该值,可以减少浏览器对元素的缓存,或者完全避免缓存。变为从始至终都重新渲染元素。使用该值时需要尽量在文档树最末尾上使用,因为该值会被应用到它所声明元素的子节点,要是在文档树较高的节点上使用的话,可能会对页面性能造成较大的影响<custom-ident>:表示开发者将要改变的元素属性。如果给定的值是缩写,则默认被扩展全,比如,will-change设置的值是padding,那么会补全所有padding的属性,如will-change: padding-top, padding-right, padding-bottom, padding-left;
详细的使用,请参阅:
- CSS Will Change Module Level 1
- Everything You Need to Know About the CSS
will-changeProperty - CSS Reference:
will-change
虽然will-change能提高性能,但这个属性应当作最后的手段,它不是为了过早的优化。只有在解决必须处理的性能问题时,才应该使用它。如果滥用反而会降低 Web 的性能。使用will-change表示该元素在未来会发生变化。如果你试图将will-change和动画同时使用,它将不会给你带来优化。因此,建议在父元素上使用will-change,在子元素上使用动画。
1 | .animate-element-parent { |
不要使用非动画元素。
当你在一个元素上使用will-change时,浏览器会尝试通过将元素移动到一个新的图层并将转换工作交互 GPU 来优化它。如果你没有任何要转换的内容,则会导致资源浪费。
除此之外,要用好will-change也不是件易事,MDN 在这方面做出了相应的描述:
- 不要将
will-change应用到太多元素上:浏览器已经尽力尝试去优化一切可以优化的东西了。有一些更强力的优化,如果与will-change结合在一起的话,有可能会消耗很多机器资源,过度使用可能导致页面响应缓慢或者消耗非常多的资源。比如*{will-change: transform, opacity;} - 有节制地使用:通常,当元素恢复到初始状态时,浏览器会丢弃掉之前做的优化工作。但是如果直接在样式表中显式声明了
will-change属性,则表示目标元素可能会经常变化,浏览器会将优化工作保存得比之前更久。所以最佳实践是当元素变化之前和之后通过脚本来切换will-change的值 - 不要过早应用
will-change优化:如果你的页面在性能方面没什么问题,则不要添加will-change属性来榨取一丁点的速度。will-change的设计初衷是作为最后的优化手段,用来尝试解决现有的性能问题。它不应该被用来预防性能问题。过度使用will-change会导致大量的内存占用,并会导致更复杂的渲染过程,因为浏览器会试图准备可能存在的变化过程。这会导致更严重的性能问题。 - 给它足够的工作时间:这个属性是用来让页面开发者告知浏览器哪些属性可能会变化的。然后浏览器可以选择在变化发生前提前去做一些优化工作。所以给浏览器一点时间去真正做这些优化工作是非常重要的。使用时需要尝试去找到一些方法提前一定时间获知元素可能发生的变化,然后为它加上
will-change属性。
最后需要注意的是,建议在完成所有动画后,将元素的will-change删除。下面这个示例展示如何使用脚本正确地应用 will-change 属性的示例,在大部分的场景中,你都应该这样做。
1 | var el = document.getElementById('element'); |
在实际使用will-change可以记作以下几个规则,即 五可做,三不可做:
- 在样式表中少用
will-change - 给
will-change足够的时间令其发挥该有的作用 - 使用
<custom-ident>来针对超特定的变化(如,left, opacity等) - 如果需要的话,可以 JavaScript 中使用它(添加和删除)
- 修改完成后,删除
will-change - 不要同时声明太多的属性
- 不要应用在太多元素上
- 不要把资源浪费在已停止变化的元素上
3. JS 避免重排重绘
① 引起回流的属性
当获取一些属性值时,浏览器为取得正确的值也会发生重排,这些属性包括:
- Element
offsetTop、offsetLeft、offsetWidth、offsetHeightscrollTop、scrollLeft、scrollWidth、scrollHeightclientTop、clientLeft、clientWidth、clientHeight
- Frame, HTMLImageElement
height、width
- Range
getBoundingClientRect(),getClientRects()
- SVGLocatable:
computeCTM()getBBox()
- SVGTextContent
getCharNumAtPosition()getComputedTextLength()getEndPositionOfChar()getExtentOfChar()getNumberOfChars()getRotationOfChar()getStartPositionOfChar()getSubStringLength()selectSubString()
- SVGUse
instanceRoot
- window
getComputedStyle()scrollBy()、scrollTo()、scrollX、scrollYwebkitConvertPointFromNodeToPage()、webkitConvertPointFromPageToNode()
更全面的属性请访问这个Gist
② 在 display:none 的元素上进行操作
如果 DOM 元素上需要进行很多操作,可以让该 DOM 元素从 DOM 树中”离线”——display:none,等操作完毕后再”上线“取消display:none。这样能去除在操作期间引发的回流与重绘。
③ 操作 cloneNode
也可以将当前节点克隆一份,操作克隆节点,操作完毕之后再替换原节点。
④ 浏览器优化
重排和重绘很容易被引起,而且重排的花销也不小,如果每句 JavaScript 操作都去重排重绘的话,浏览器可能就会受不了。所以很多浏览器都会优化这些操作,浏览器会维护一个队列,把所有会引起重排、重绘的操作放入这个队列,等队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会 flush 队列,进行一个批处理。这样就会让多次的重排、重绘变成一次重排重绘。
1 | var dom = document.querySelector("#dom"); |
⑤ 通过样式去改变元素样式
1 | // bad |
上述例子每次修改 style 属性后都会触发元素的重绘,如果修改了的属性涉及大小和位置,将会导致回流。所以我们应当尽量避免多次为一个元素设置 style 属性,应当通过给其添加新的 CSS 类,来修改其样式。
1 | <!--better--> |
4. 简化 DOM 结构
首先每个 DOM 对象的都会占据浏览器资源,占据的资源与数量成正相关。另外,DOM 结构越深,最里面 DOM 元素的变化可能引发的祖先 DOM 数量就越多。
使用场景例如大量数据表格的展示,几万个 DOM 就能把浏览器卡得不要不要的甚至直接奔溃。我曾经遇到这样真实的案例,后在保持后端接口不变的情况下,采用前端假分页解决。
5. DOM 事件优化
① 使用事件委托或事件代理
使用事件代理与每个元素都绑定事件相比,能够节省更多的内存。当然还有另外的好处,就是新增加假的 DOM 元素也无需绑定事件了,这里不详述。
② 节流函数
首先这样场景下,在页面滚动的时候需根据页面滚动位置做一些操作,但是 scroll 事件触发过于频繁,导致绑定的事件执行频率太高开销太大。我们就需要采取一些措施来降低事件被执行的频率。
节流实际上就降低函数触发的频率。
1 | let throttle = (func, wait) => { |
③ 防抖函数
说道节流,不得不提防抖,相交于节流的降低触发的频率,防抖函数实际上是延后函数执行的时机,一般情况下,防抖比截流更节省性能。
1 | let debounce = (func, wait) => { |
使用场景例如一个输入框的实时搜索,对用户而言其实想要输入的关键词是输入完成的最终结果,而程序需要实时针对用户输入的无效关键词进行响应,这无疑是种浪费。
(八)SEO 优化
19. SSR
渲染过程在服务器端完成,最终的渲染结果 HTML 页面通过 HTTP 协议发送给客户端,又被认为是‘同构’或‘通用’,如果你的项目有大量的 detail 页面,相互特别频繁,建议选择服务端渲染。
服务端渲染 (SSR) 除了 SEO 还有很多时候用作首屏优化,加快首屏速度,提高用户体验。但是对服务器有要求,网络传输数据量大,占用部分服务器运算资源。
Vue 的 Nuxt.js 和 React 的 next.js 都是服务端渲染的方法。
20. UNPKG
UNPKG 是一个提供 npm 包进行 CDN 加速的站点,因此,可以将一些比较固定了依赖写入 html 模版中,从而提高网页的性能。首先,需要将这些依赖声明为 external,以便 webpack 打包时不从 node_modules 中加载这些资源,配置如下:
1 | externals: { 'react': 'React' } |
其次,你需要将所依赖的资源写在 html 模版中,这一步需要用到html-webpack-plugin。下面是一段示例:
1 | <% if (htmlWebpackPlugin.options.node_env === 'development') { %> |
这段代码需要注入 node_env,以便在开发的时候能够获得更友好的错误提示。也可以选择一些比较自动的库,来帮助我们完成这个过程,比如webpack-cdn-plugin,或者dynamic-cdn-webpack-plugin。