渲染真实 DOM(Document Object Model)的开销是很大的。有时修改某个数据,如果直接渲染到真实 DOM 上会引起整个 DOM 树的重绘和重排。而 diff 算法可以只更新修改的那一小块 DOM,而非更新整个 DOM。
1. 虚拟 DOM 虚拟 DOM 是一种前端性能优化的手段,常用于 React 等框架中。它是一个用 JS 对象模拟真实 DOM 的结构和属性的技术。它可以在内存中进行 DOM 的操作,提高渲染效率。它通过 diff 算法,计算出最小的 DOM 变化,然后再更新到真实的 DOM 上。
我们会根据真实 DOM 生成一棵 virtual DOM,当 virtual DOM 某个节点的数据改变后会生成一个新的 Vnode,然后将 Vnode 和 old Vnode 作对比,发现有不一样的地方就直接修改在真实的 DOM 上,然后使 old Vnode 的值为 Vnode。diff 的过程就是调用名为 patch 的函数,比较新旧节点,一边比较一边给真实 DOM 打补丁。
而虚拟 DOM 是一个用来表示真实 DOM 的对象,它将真实的 DOM 数据抽取出来,以对象的形式模拟树形结构,记录新树和旧树的差异,最后把差异更新到真正的 DOM 中。比如 DOM 是这样的:
1 2 3 <div id ="list" > <p class ="item" > 123</p > </div >
则对应的 virtual DOM 如下:
1 2 3 4 5 6 7 8 9 var Vnode = { tag: 'div' , props: { id: 'list' }, children: [ { tag : 'p' , props : { class : 'item' }, text : '123' } ] };
注意,VNode 和 old VNode 都是对象。
diff 算法在比较新旧节点时,只会在同层级进行比较,而不会跨层级比较。
1 2 3 <div > <p > 123</p > </div >
1 2 3 <div > <span > 456</span > </div >
如上,代码会分别比较第一层的两个 div,然后比较第二层的 p 和 span,但不会拿 div 和 span 作比较。
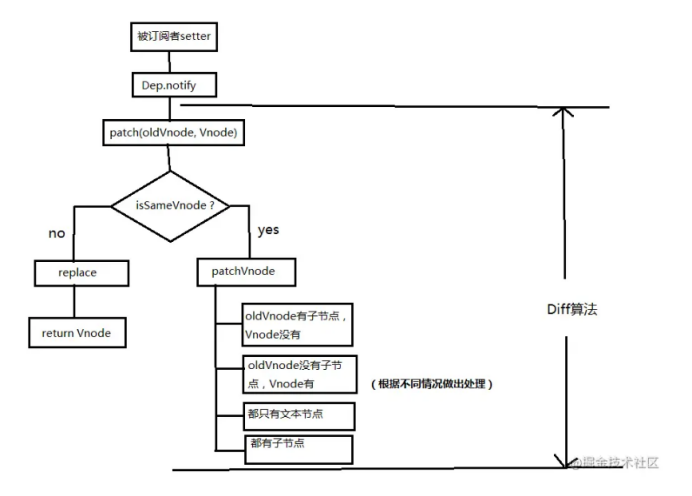
2. diff 流程 当数据改变时,set 方法会调用 Dep.notify 通知所有订阅者 Watcher,接着订阅者会调用 patch 给真实 DOM 打补丁,更新相应视图。
patch()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 function patch (oldVnode, vnode ) if (sameVnode(oldVnode, vnode)) { patchVnode(oldVnode, vnode) } else { const oEl = oldVnode.el let parentEle = api.parentNode(oEl) createEle(vnode) if (parentEle !== null ) { api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)) api.removeChild(parentEle, oldVnode.el) oldVnode = null } } return vnode }
patch 函数接收两个参数 old Vnode 和 Vnode,分别代表旧节点和新节点。sameVnode 函数判断两个节点是否为同一个 Vnode。如果是,则执行 patchVnode,否则直接用 Vnode 替换 old Vnode。
sameVnode()1 2 3 4 5 6 7 8 9 function sameVnode (a, b ) return ( a.key === b.key && a.tag === b.tag && a.isComment === b.isComment && isDef(a.data) === isDef(b.data) && sameInputType(a, b) ) }
如果两个节点信息不一致,那就说明 DOM 被改变了,Vnode 将直接替换 old Vnode。因此,如果两个节点信息不一致,就算它们拥有相同的子节点,diff 算法都会整个直接替换,而不会考虑复用子节点。
而如果两个节点的 key 值和标签名等都一致,说明它们是同一个 Vnode,那么就开始执行 patchVnode 方法。
patchVnode()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 patchVnode (oldVnode, vnode) { const el = realDOM let i, oldCh = oldVnode.children, ch = vnode.children if (oldVnode === vnode) return if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) { api.setTextContent(el, vnode.text) } else { updateEle(el, vnode, oldVnode) if (oldCh && ch && oldCh !== ch) { updateChildren(el, oldCh, ch) } else if (ch){ createEle(vnode) } else if (oldCh){ api.removeChildren(el) } } }
这个方法主要做了以下事情:
找到对应的真实 DOM,称为 el; 判断 vnode 和 oldvnode 是否全等或者说指向同一个对象,如果是,则直接 return; 如果它们都有文本节点且不相等,那么将 el 的文本节点设置为 vnode 的文本节点; 如果 oldvnode 有子节点,而 vnode 没有,则删除 el 的子节点; 如果 vnode 有子节点,而 oldvnode 没有,则将子节点真实化后添加到 el; 如果两者都有子节点,则执行 updateChildren 函数比较子节点。 updateChildren()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 updateChildren (parentElm, oldCh, newCh) { let oldStartIdx = 0 , newStartIdx = 0 let oldEndIdx = oldCh.length - 1 , newEndIdx = newCh.length - 1 let oldStartVnode = oldCh[0 ], newStartVnode = newCh[0 ] let oldEndVnode = oldCh[oldEndIdx], newEndVnode = newCh[newEndIdx] let oldKeyToIdx let idxInOld let elmToMove let before while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (oldStartVnode == null ) { oldStartVnode = oldCh[++oldStartIdx] }else if (oldEndVnode == null ) { oldEndVnode = oldCh[--oldEndIdx] }else if (newStartVnode == null ) { newStartVnode = newCh[++newStartIdx] }else if (newEndVnode == null ) { newEndVnode = newCh[--newEndIdx] }else if (sameVnode(oldStartVnode, newStartVnode)) { patchVnode(oldStartVnode, newStartVnode) oldStartVnode = oldCh[++oldStartIdx] newStartVnode = newCh[++newStartIdx] }else if (sameVnode(oldEndVnode, newEndVnode)) { patchVnode(oldEndVnode, newEndVnode) oldEndVnode = oldCh[--oldEndIdx] newEndVnode = newCh[--newEndIdx] }else if (sameVnode(oldStartVnode, newEndVnode)) { patchVnode(oldStartVnode, newEndVnode) api.insertBefore(parentElm, oldStartVnode.el, api.nextSibling(oldEndVnode.el)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] }else if (sameVnode(oldEndVnode, newStartVnode)) { patchVnode(oldEndVnode, newStartVnode) api.insertBefore(parentElm, oldEndVnode.el, oldStartVnode.el) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] }else { if (oldKeyToIdx === undefined ) { oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) } idxInOld = oldKeyToIdx[newStartVnode.key] if (!idxInOld) { api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el) newStartVnode = newCh[++newStartIdx] } else { elmToMove = oldCh[idxInOld] if (elmToMove.sel !== newStartVnode.sel) { api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el) }else { patchVnode(elmToMove, newStartVnode) oldCh[idxInOld] = null api.insertBefore(parentElm, elmToMove.el, oldStartVnode.el) } newStartVnode = newCh[++newStartIdx] } } } if (oldStartIdx > oldEndIdx) { before = newCh[newEndIdx + 1 ] == null ? null : newCh[newEndIdx + 1 ].el addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx) }else if (newStartIdx > newEndIdx) { removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx) } }
这个方法究竟做了什么呢?下面让我们好好说道。
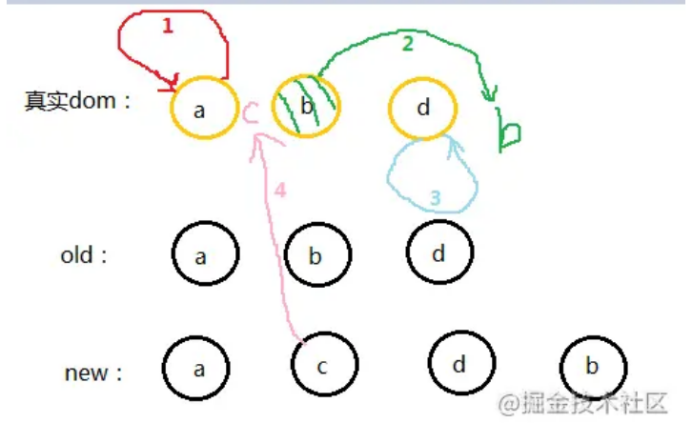
假设有 old Vnode 和 Vnode 如下,粉色和黄色部分分别是它们对应的子节点。
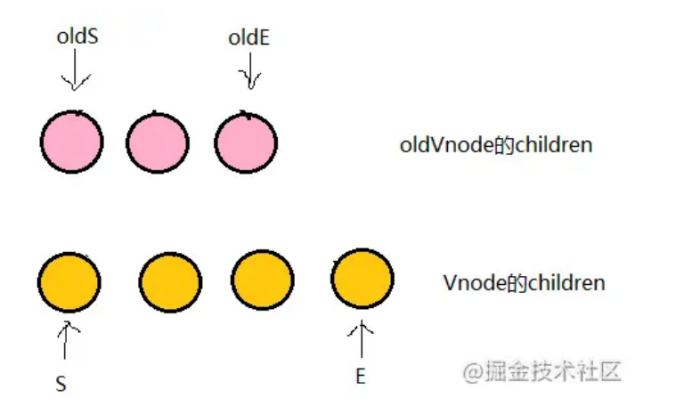
将它们的子节点取出,并分别用 s 和 e 指针指向队首和队尾节点。
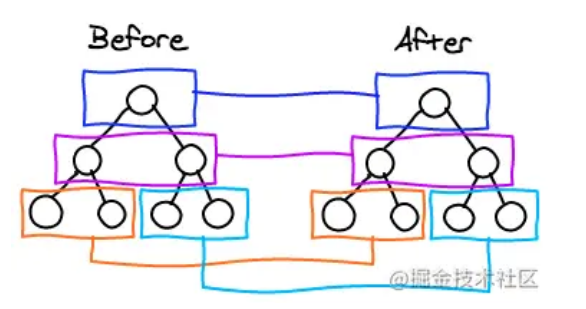
现在分别将 oldS、oldE 和 S、E 两两做 sameVnode 比较,即一共有 4 种比较方式。当其中两个能匹配上,那么真实 DOM 中的相应节点会移到 Vnode 相应的位置。
如果是 oldS 和 E 匹配上了,那么将执行 patchVnode(oldS, E),同时真实 DOM 中的第一个节点会移到队尾,匹配上的两个指针向中间移动; 如果是 oldE 和 S 匹配上了,那么将执行 patchVnode(oldE, S),同时真实 DOM 中的最后一个节点会移到最前,匹配上的两个指针向中间移动。 如果四种匹配没有一对是成功的,则又可分为两种情况:
如果新旧子节点都存在 key,那么会根据 oldChild 的 key 生成一张 hash 表,用 S 的 key 与 hash 表做匹配,匹配成功就判断 S 和匹配节点是否为 sameNode。如果是,就在真实 DOM 中将该节点移到最前面,否则将 S 生成对应的节点插入到 DOM 中对应的 oldS 位置,S 指针向中间移动,被匹配 old 中的节点置为 null。 如果没有 key,则直接将 S 生成新节点插入真实 DOM(ps:这下可以解释为什么 v-for 需要设置 key 了,如果没有 key 那么就只会做四种匹配,就算指针中间有可复用的节点都不能被复用了) 这里再给出一个例子说明。
假设下图中所有节点都带有 key,且 key 为自身的值。
1 2 oldS = a, oldE = d; S = a, E = b;
① oldS 和 S 匹配,则将 DOM 中的 a 节点保持在队首,此时 DOM 的位置为:a b d。oldS 和 S 都往右移一位。
1 2 oldS = b, oldE = d; S = c, E = b;
② oldS 和 E 匹配,就将原本的 b 节点移动到队尾,此时 DOM 的位置为:a d b。oldS 和 S 都往内部移动一位。
1 2 oldS = oldE = d; S = c, E = d;
③ oldE 和 E 匹配,位置不变,此时 DOM 的位置为:a d b。
1 2 3 oldS++; oldE--; oldS > oldE;
④ 遍历结束,oldCh 先遍历完,则将剩余的 vCh 节点根据自己的的 index 插入到真实 DOM 中去,此时 DOM 位置为:a c d b。
这个匹配过程的结束有两种结果:
oldS > oldE:表示 oldCh 先遍历完,那么就将多余的 vCh 根据 index 添加到 DOM 中去; S > E:表示 vCh 先遍历完,那么就在真实 DOM 中将区间为 [oldS, oldE] 的多余节点删掉。 3. v-for 的 key 平常使用 v-for 循环渲染时,并不建议使用 index 来作为循环项的 key。
假设有初始数据如下:
1 2 3 4 5 <ul > <li key ="0" > a</li > <li key ="1" > b</li > <li key ="2" > c</li > </ul >
现在要往列表头部插入一个新数据,如下:
1 2 3 4 5 6 <ul > <li key ="0" > test</li > <li key ="1" > a</li > <li key ="2" > b</li > <li key ="3" > c</li > </ul >
操作 DOM 效率最高的一种方式无非是只插入一个 li 标签的新节点,而其它节点都不变。但如果使用 index 来作为 key 值,将导致所有的 li 数据都会更新。
根据 diff 算法过程,首先会执行 sameVnode(oldUl, newUl) 比对 ul 元素,逻辑结果为真,于是执行 patchVnode(oldUl, newUl),发现两者都有子节点,于是执行 updateChildren(el, oldCh, ch) 。
接着执行 sameVnode(oldS, S) ,因为这两个子节点的 key 都是 0,所以命中了逻辑。同理,之后 key 为 1 和 2 的也会命中逻辑,这就导致相同 key 的节点会去调用 patchVnode 方法,然后发现文本节点不一致,于是更新了文本。而 key 为 3 的节点被当作新节点,插入到了真实 DOM 中。
因此前三个 li 都使用了 patchVnode 更新文本,而最后一个进行了新增,也就导致了所有 li 都更新。这也提醒我们,应使用独一无二的 id 值来作为 key。