PWA 详解
1. PWA 概述
PWA(Progressive Web Application,渐进式网页应用) 不是特指某一项技术,而是应用了多项技术的 Web App。其核心技术包括 App Manifest、Service Worker、Web Push等。自 2015 年以来,PWA 相关的技术不断升级优化,在用户体验和用户留存两方面都提供了非常好的解决方案。PWA 可以将 Web 和 App 各自的优势融合在一起:渐进式、可响应、可离线、实现类似 App 的交互、即时更新、安全、可以被搜索引擎检索、可推送、可安装、可链接。
Native APP 尽管使用流畅,但还是存在如下缺陷:
- 由于其天生封闭的基因,内容无法被索引
- 用户绝大多数时间都被 Top 级别的 App 占据,对于站点来说,应用分发的性价比越来越不划算
- 要使用它,首先还需要下载几十兆以上的安装包
而 WEB 前端虽然天生具有开放的基因,但很多时候页面会卡顿,用户体验不佳。尽管社区通过
virtual dom、spa、混合编程、canvas绘制页面等方案,大幅改善了用户体验,但仍然无法解决几个重要问题:
- 离线时用户无法使用
- 无法接收消息推送
- 移动端没有一级入口
W3C 和谷歌因此推出PWA来提升 Web App 的性能,改善 Web App 的用户体验。PWA 具有如下一些特点:
PWA 可以像原生 APP 一样可安装,即在主屏幕上留有图标。但这需要借助 Web app manifest。manifest.json 是一个简单的JSON文件,在 html 页面如下引用它。
1 | <link rel="manifest" href="/manifest.json"> |
manifest.json描述了应用图标在主屏幕上如何显示,以及点击图标后的启动页是什么,具体格式如下:
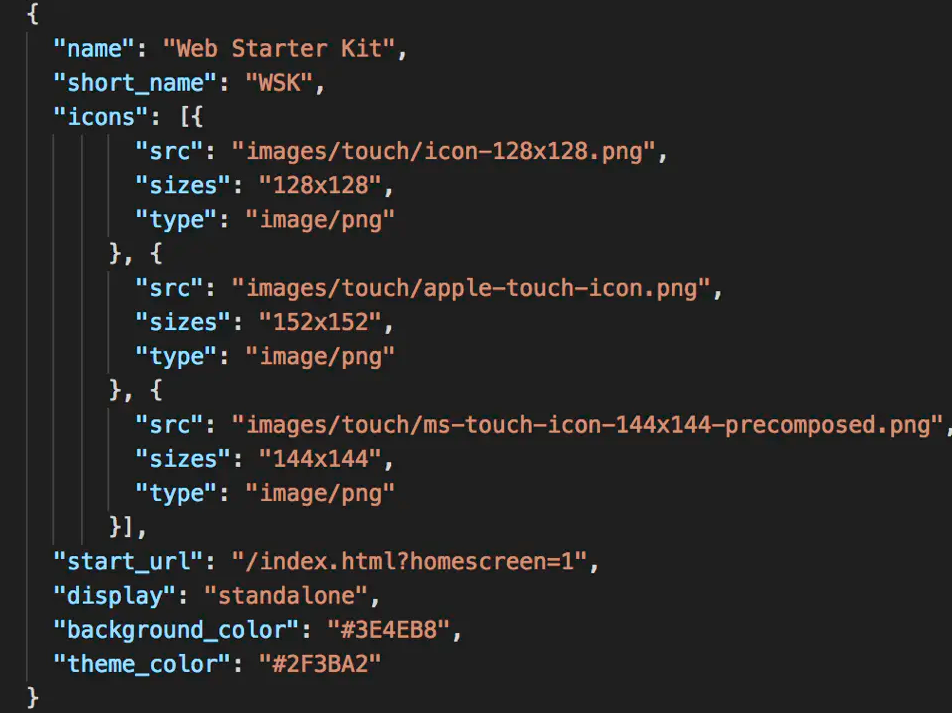
start_url:可以设置启动网址icons:设置各个分辨率下页面的图标background_color:会设置背景颜色, Chrome 在网络应用启动后会立即使用此颜色,这一颜色将保留在屏幕上,直至网络应用首次呈现为止。theme_color:会设置主题颜色display:设置启动样式
关于manifest.json里字段更具体的含义,可参考MDN文档或谷歌开发者文档说明。
比如豆瓣移动端就是一个PWA应用,如果用高版本的浏览器打开,就会出现manifest的横幅提示。打开豆瓣后,浏览器会提示是否添加到主屏幕。
点击确定后,提示添加成功,然后在主屏幕上留有豆瓣的图标。
2. service worker
PWA 可以离线使用,其背后用到的技术是 Service worker 。Service Worker 使得 Web App 实现了 Native App 的离线使用和消息推送功能。我们可以把Service worker当做是一种客户端代理。
service worker 是浏览器的一个高级特性,本质是一个 web worker,是独立于网页运行的脚本。 web worker 这个API被造出来时,就是为了解放主线程。因为浏览器中的 JavaScript 都是运行在单个线程上,随着 web 业务变得愈发复杂,js 中耗时耗资源的运算过程会导致各种性能问题。 而 web worker 由于独立于主线程,可以将一些复杂的逻辑交由它去做,完成后再通过postMessage告诉主线程。 service worker 则是 web worker 的升级版本,相较于后者,前者拥有了持久离线缓存的能力。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。合理实用 web worker 可以优化复杂计算任务。这里直接抛阮一峰的入门文章:传送门
① 特点
- 脚本独立于主线程,在后台运行,不能直接参与 Web 交互行为(如访问 dom 或窗口 window);
- 被安装后便永远存在,除非手动卸载;
- 可编程拦截请求和返回,缓存文件。service worker 可以通过 fetch API,来拦截网络和处理网络请求,再配合
cacheStorage来实现 web 页面的缓存管理以及与前端postMessage通信; - 只能使用 https 协议。不过本地调试时,在
http://localhost和http://127.0.0.1下也可以跑起来; - 异步实现,service worker 大量使用 promise。
② 生命周期
service worker 从代码编写,到在浏览器中运行,经过的阶段有: installing -> installed -> activating -> activated -> redundant。
- **installing: **This stage marks the beginning of registration. It’s intended to allow to setup worker specific resources such as offline caches. 在这个过程会触发 install 事件回调,指定一些静态资源进行离线缓存。
- installed: The service worker has finished its setup and it’s waiting for clients using other service workers to be closed.(在 install 事件回调中,可以调用
skipWaiting方法来跳过 waiting 阶段) - activating: There are no clients controlled by other worker. This stage is intended to allow the worker to finish the setup or clean other worker’s related resources like removing old caches.
- activated: 在这个状态会处理 activate 事件回调。This service worker can now handle functional events, like fetch, sync and push。(在 active 的事件回调中,可以调用
self.clients.claim()) - redundant: This service worker is being replaced by another one.
③ 代码实现
1 | //在页面代码里面监听onload事件,使用service worker的配置文件注册一个service worker |
1 | //serviceWorker.js |
④ webpack 配置
真正要在正式环境上使用时,可以借助一个 webpack 插件:workbox-webpack-plugin。workbox 是 google 官方的 PWA 框架,workbox-webpack-plugin是由其产生的工具之一,内置了两个插件:GenerateSW 、InjectManifest
GenerateSW:这个插件会生成一个 service worker 配置文件,主要处理文件缓存和 install、activateInjectManifest:这个插件可以自定义更多的配置,比如 fetch、push、sync 事件
这里是为了进行资源缓存,所以只使用GenerateSW这部分。
1 | //在webpack配置文件里 |
importWorkboxFrom:workbox 框架文件的地址,可选cdn、local、disabled
cdn:引入 google 的官方 CDN,在国内会被 banlocal:workbox Plugin 会在本地生成 workbox 代码,可以将这些配置文件一起上传部署,这样每次都要部署生成的代码disabled:上面两种都不选用,将生成出来的 workbox 代码使用 import script 指定 js 文件从而引入。
建议使用第三种,因为这样可以由自己指定从哪里引入,如果以后这个站点有了 CDN,可以将这个 workbox.js 放到 CDN 上。目前是将生成的文件,放到 script 文件夹下。
workbox 的策略
- Stale-While-Revalidate:尽可能快地利用缓存返回响应,缓存无效时则使用网络请求
- Cache-First:缓存优先
- Network-First:网络优先
- Network-Only:只使用网络请求的资源
- Cache-Only:只使用缓存
一般站点的 CSS,JS 都在 CDN 上,SW 并没有办法判断从 CDN 上请求下来的资源是否正确(HTTP 200),如果缓存了失败的结果,就不好了。这种情况下使用 stale-while-Revalidate 策略,既保证了页面速度,即便失败,用户刷新一下就更新了。而由于种子项目的 js 和 css 资源都在站点下面,所以这里就直接使用了 cache-first 策略。
在 webpack 中配置好后,执行 webpack 打包,就能看到在指定目录下由 workbox-webpack-plugin 生成的 service worker 配置文件。
接入之后,打开网站,在电脑端的chrome调试工具上可以看到缓存的资源
service worker 一旦被 install,就永远存在;如果有一天想要去除跑在浏览器背后的这个 service worker 线程,要手动去卸载。所以在接入之前,得先知道如何卸载 service worker:
1 | if ('serviceWorker' in navigator) { |
使用 service worker 缓存了资源,那下次重新发布了,还会不会拉取新的资源呢?这里也是可以的,只要资源地址不一样、修改了 hash值,那么资源是会重新去拉取并进行缓存的,如下图,可以看到对同一个js的不同版本,都进行了缓存。
还有个就是对于考虑开发过程的问题,如果以后上线了,service worker 这个东西安装下去了,每次打开都直接读取缓存的资源,那以后在本地调试时怎办?试了下,chrome 的 “disabled cache” 也没有用,总不能在本地开发时也给资源打上 hash 值吧(目前这个项目是在发布到正式环境时才会打上hash值)。其实 chrome 早有这个设置,在 devtool 中可以设置跳过 service worker:bypass for network
比起浏览器的默认缓存功能,service worker 的缓存功能赋予我们更强的控制缓存的能力。然而不足在于,还没有很多浏览器支持 service worker,苹果系统是从11.3才开始支持。
⑤ 查看设置
在 Chrome浏览器的开发者工具里有一个Audits面板,它可以帮我们检测网页是否具备了 PWA 的一些特点:
分割线…………………………………………………………………………………………………………………………………………………..
Service Worker
什么是 Service Worker
Service Worker 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。
Service worker 可以解决目前离线应用的问题,同时也可以做更多的事。 Service Worker 可以使你的应用先访问本地缓存资源,所以在离线状态时,在没有通过网络接收到更多的数据前,仍可以提供基本的功能(一般称之为 Offline First)。这是原生APP 本来就支持的功能,这也是相比于 web app ,原生 app 更受青睐的主要原因。
再来看看 👀 service worker 能做些什么:
- 后台消息传递
- 网络代理,转发请求,伪造响应
- 离线缓存
- 消息推送
- … …
本文主要以(lishaoy.net)资源缓存为例,阐述下 service worker如何工作
生命周期
service worker 初次安装的生命周期,如图 🌠
sw生命周期
从上 👆 图可知,service worker 工作的流程:
安装:
service worker URL通过serviceWorkerContainer.register()来获取和注册。激活: 当
service worker安装完成后,会接收到一个激活事件(activate event)。onactivate主要用途是清理先前版本的service worker脚本中使用的资源。监听:
两种状态
- 终止以节省内存;
- 监听获取
fetch和消息message事件。
销毁: 是否销毁由浏览器决定,如果一个
service worker长期不使用或者机器内存有限,则可能会销毁这个worker。
Tips:激活成功之后,在 Chrome 浏览器里,可以访问 chrome://inspect/#service-workers和 chrome://serviceworker-internals/ 可以查看到当前运行的service worker ,如图 👇。
现在,我们来写个简单的例子 🌰
注册 service worker
要安装 service worker ,你需要在你的页面上注册它。这个步骤告诉浏览器你的 service worker 脚本在哪里。
1 | if ('serviceWorker' in navigator) { |
上面的代码检查 service worker API 是否可用,如果可用,service worker /sw.js 被注册。如果这个 service worker 已经被注册过,浏览器会自动忽略上面的代码。
激活 service worker
在你的 service worker 注册之后,浏览器会尝试为你的页面或站点安装并激活它。 install 事件会在安装完成之后触发。install 事件一般是被用来填充你的浏览器的离线缓存能力。你需要为 install 事件定义一个 callback ,并决定哪些文件你想要缓存.
1 | // The files we want to cache |
在我们的 install callback 中,我们需要执行以下步骤:
- 开启一个缓存
- 缓存我们的文件
- 决定是否所有的资源是否要被缓存
上面的代码中,我们通过 caches.open 打开我们指定的 cache 文件名,然后我们调用 cache.addAll 并传入我们的文件数组。这是通过一连串 promise (caches.open 和 cache.addAll) 完成的。event.waitUntil 拿到一个 promise 并使用它来获得安装耗费的时间以及是否安装成功。
监听 service worker
现在我们已经将你的站点资源缓存了,你需要告诉 service worker 让它用这些缓存内容来做点什么。有了fetch 事件,这是很容易做到的。
每次任何被 service worker 控制的资源被请求到时,都会触发 fetch 事件,我们可以给 service worker 添加一个 fetch 的事件监听器,接着调用 event 上的 respondWith() 方法来劫持我们的 HTTP 响应,然后你用可以用自己的方法来更新他们。
1 | self.addEventListener('fetch', function(event) { |
caches.match(event.request) 允许我们对网络请求的资源和 cache 里可获取的资源进行匹配,查看是否缓存中有相应的资源。这个匹配通过 url 和 vary header 进行,就像正常的 HTTP 请求一样。
那么,我们如何返回 request 呢,下面 👇 就是一个例子 🌰
1 | self.addEventListener('fetch', function(event) { |
上面的代码里我们定义了 fetch 事件,在 event.respondWith 里,我们传入了一个由 caches.match 产生的 promise.caches.match 查找 request 中被 service worker 缓存命中的 response 。 如果我们有一个命中的 response ,我们返回被缓存的值,否则我们返回一个实时从网络请求 fetch 的结果。
sw-toolbox
当然,我也可以使用第三方库,例如:lishaoy.net 使用了 sw-toolbox。
sw-toolbox 使用非常简单,下面 👇 就是 lishaoy.net 的一个例子 🌰
1 | "serviceWorker" in navigator ? navigator.serviceWorker.register('/sw.js').then(function () { |
以上是 注册 一个 service woker
1 | ; |
就这样搞定了 🍉 (具体的用法可以去 sw-toolbox 查看)
有的同学就问,service worker 这么好用,这个缓存空间到底是多大?其实,在 Chrome 可以看到,如图
可以看到,大概有 30G ,我的站点只用了 183MB ,完全够用了 🍓
最后,来两张图
由于,文章篇幅过长,后续还会继续总结 架构 方面的优化,例如
- bigpipe分块输出
- bigrender分块渲染
- …
以及,渲染 方面的优化,例如
- requestAnimationFrame
- well-change
- 硬件加速 GPU
- …
以及,性能测试工具,例如
- PageSpeed
- audits
- …